📝 Paper Summary
Sequential Recommendation
Loss Functions
Traditional sequential recommenders trained with Cross-Entropy loss outperform LLM-based recommenders, and a new Scaled Cross-Entropy loss allows them to scale efficiently while maintaining this superiority.
Core Problem
Prior comparisons between LLM-based recommenders and traditional models are unfair because traditional models are typically trained with suboptimal pointwise/pairwise losses (BCE/BPR) while LLMs use Cross-Entropy (CE).
Why it matters:
- Leads to over-confidence in LLM ranking capabilities and massive computational waste
- Underestimates the potential of efficient traditional architectures like SASRec when properly optimized
- Existing sampling methods for large item spaces (like sampled softmax) often degrade performance due to poor tightness
Concrete Example:
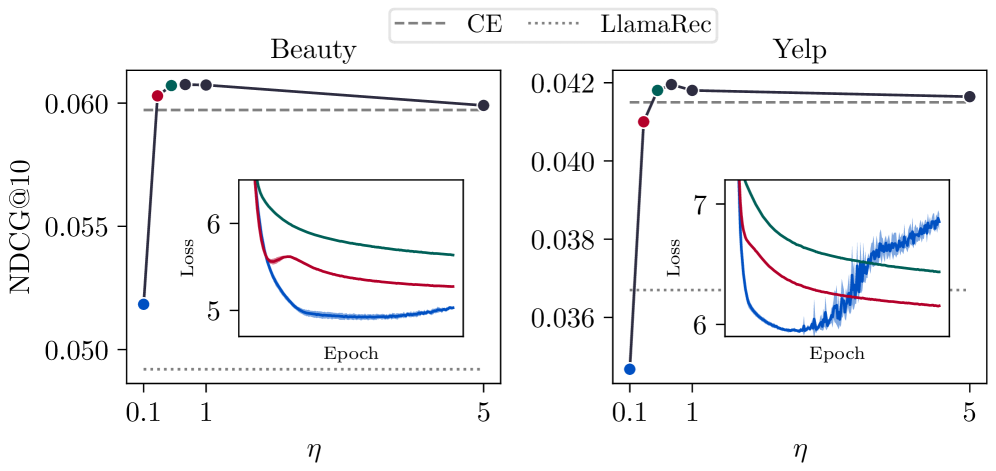
When trained with BCE, SASRec underperforms LlamaRec on the Beauty dataset. However, simply switching SASRec's loss to full softmax Cross-Entropy allows it to surpass LlamaRec, revealing that the performance gap was due to the loss function, not model architecture.
Key Novelty
Scaled Cross-Entropy (SCE) for Sequential Recommendation
- Demonstrates theoretically that an ideal recommendation loss requires both 'tightness' (good proxy for ranking metrics) and 'coverage' (sufficient negative samples)
- Proposes Scaled Cross-Entropy (SCE) which scales up the sampled normalization term to approximate the tightness of full softmax while maintaining efficiency
- Re-benchmarks traditional models (SASRec, FMLP-Rec) with CE/SCE, proving they outperform fine-tuned LLMs
Architecture
A conceptual illustration distinguishing different loss functions based on Tightness and Coverage properties.
Evaluation Highlights
- Traditional SASRec with Cross-Entropy outperforms fine-tuned LlamaRec (7B) by ~23% on Beauty dataset (NDCG@5: 0.0886 vs 0.0718)
- Proposed SCE loss matches full Cross-Entropy performance with only 500 negative samples, while standard Sampled Softmax degrades significantly
- FMLP-Rec with Cross-Entropy achieves state-of-the-art results on Yelp, surpassing P5 and LlamaRec
Breakthrough Assessment
8/10
Strongly challenges the prevailing narrative that LLMs are superior for sequential recommendation by exposing a fundamental flaw in baseline comparisons. Offers a simple, effective fix (SCE) that restores the viability of traditional models.