📝 Paper Summary
LLM-based Recommendation
Bias and Fairness in Recommender Systems
GDRT is a fine-tuning strategy that uses Group Distributionally Robust Optimization to force LLMs to rely on user interaction history rather than shortcut correlations with auxiliary prompt text.
Core Problem
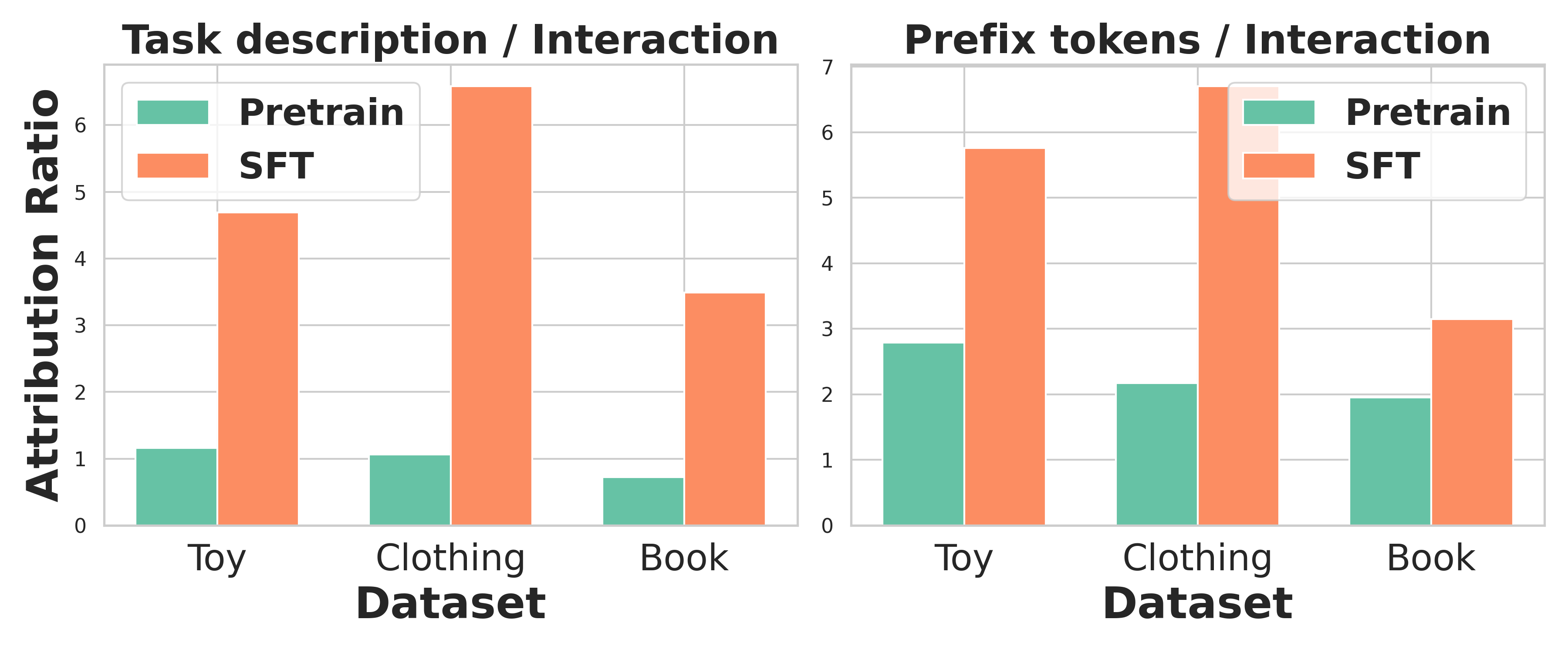
Supervised fine-tuning causes LLM recommenders to over-rely on static 'auxiliary tokens' (task descriptions, prefixes) instead of user-specific interaction history, leading to 'context bias'.
Why it matters:
- Recommendations become non-personalized because the model ignores the user's history in favor of prompt artifacts
- Creates unfairness by recommending only items whose titles happen to correlate with the fixed task prompt instructions
- Standard fine-tuning amplifies this bias significantly (e.g., attribution ratio shifts from 1:1 to 6:1 on Amazon datasets)
Concrete Example:
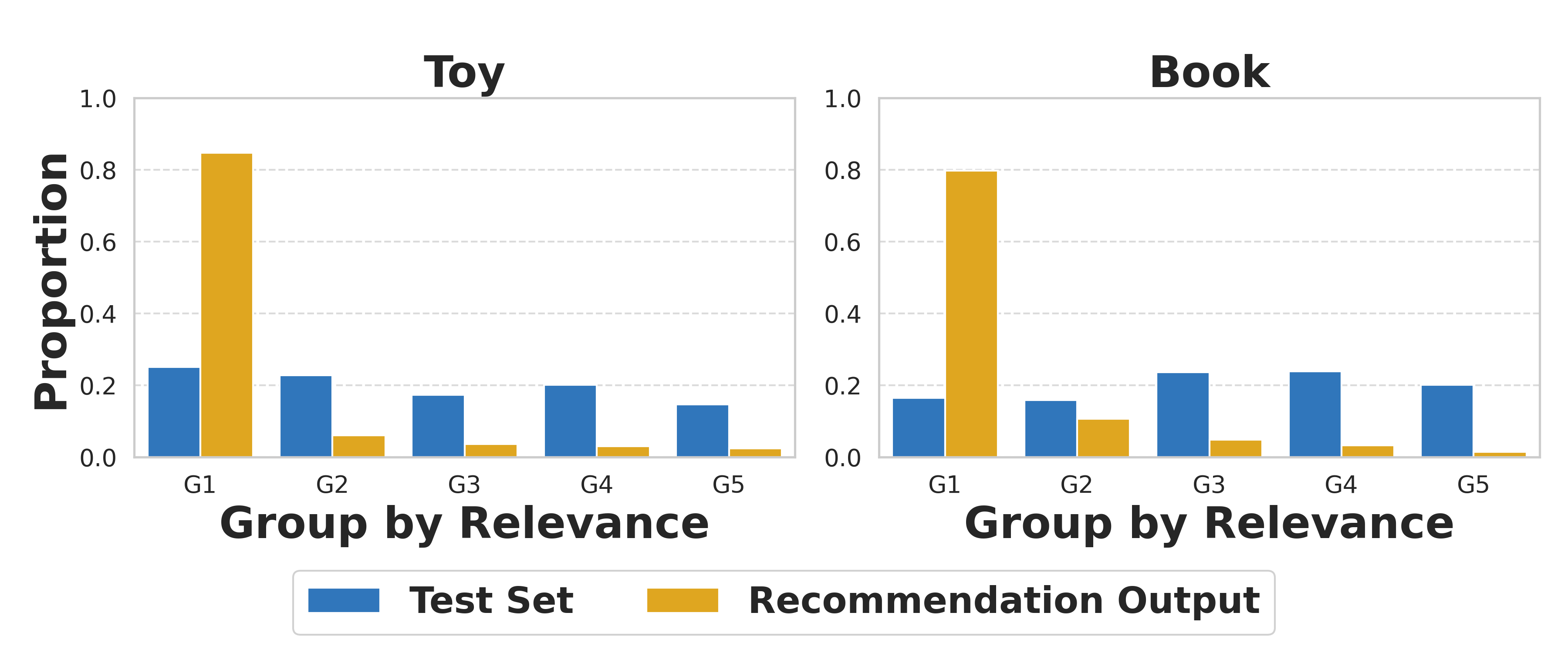
In a dataset where the prompt always contains 'prediction:', the LLM learns to predict items that frequently co-occur with the word 'prediction:' rather than items matching the user's history. As a result, 80% of recommendations might come from just the top 20% of items that have high semantic overlap with the prompt text.
Key Novelty
Group Distributionally Robust Optimization for Tuning (GDRT)
- Groups training samples based on how strongly the target item correlates with the auxiliary prompt text (measured by the LLM's probability when history is masked)
- Applies Group DRO to dynamically upweight the loss of 'hard' groups (items with weak correlation to the prompt), forcing the model to learn from user history instead of taking the easy shortcut
Architecture
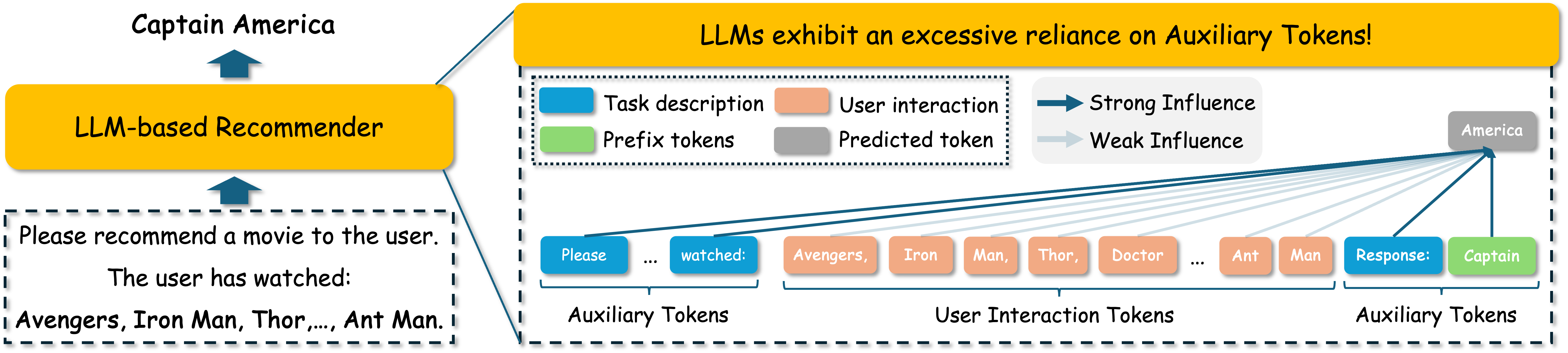
Illustrates the concept of Context Bias in LLM-based recommendation.
Evaluation Highlights
- Achieves an average NDCG@10 gain of 24.29% across three public datasets compared to standard SFT
- Reduces unfairness significantly: standard deviation of group performance drops from ~0.08 (SFT) to ~0.01 (GDRT) on Amazon Beauty
- Outperforms state-of-the-art bias mitigation method (CFT) by substantial margins (e.g., +0.0345 NDCG@10 on Amazon Beauty)
Breakthrough Assessment
8/10
Identifies a distinct, previously overlooked bias type ('Context Bias') in LLM recommenders and provides a theoretically grounded, highly effective solution that improves both accuracy and fairness simultaneously.