📝 Paper Summary
Agentic Recommender Systems
Evaluation Benchmarks
AgentRecBench introduces a standardized textual simulator and modular framework to evaluate agentic recommender systems across diverse scenarios, revealing that agents outperform traditional models in cold-start and dynamic tasks.
Core Problem
The field of agentic recommender systems lacks standardized evaluation protocols, making it difficult to systematically assess how well agents generalize across complex scenarios compared to traditional methods.
Why it matters:
- Traditional metrics rely on static historical data, failing to capture an agent's ability to actively gather information and adapt to evolving user interests.
- Existing evaluations often lack diverse scenarios (e.g., cold-start vs. evolving interests), hindering understanding of where agentic approaches truly excel.
- The absence of a unified simulation environment limits reproducibility and comparable research in developing autonomous recommendation agents.
Concrete Example:
In a user cold-start scenario where a new user has only one or two interactions, traditional Matrix Factorization fails due to data sparsity. An agentic system, however, can proactively query the environment for the user's profile text or reviews to infer preferences, but current static benchmarks cannot measure this interactive capability.
Key Novelty
AgentRecBench: A Unified Interactive Benchmark for Agentic Recommendation
- Constructs a textual interaction environment (User-Review-Item network) that allows agents to actively query standardized interfaces (e.g., search user, get reviews) rather than just processing static datasets.
- Proposes a modular agent framework abstracting core cognitive components (Planning, Reasoning, Tool Use, Memory) to facilitate rapid prototyping of different agent architectures.
- Implements dynamic data visibility control to create specific evaluation scenarios like 'evolving interests' (filtering data by time) and 'cold-start' (restricting interaction history) within the same environment.
Architecture
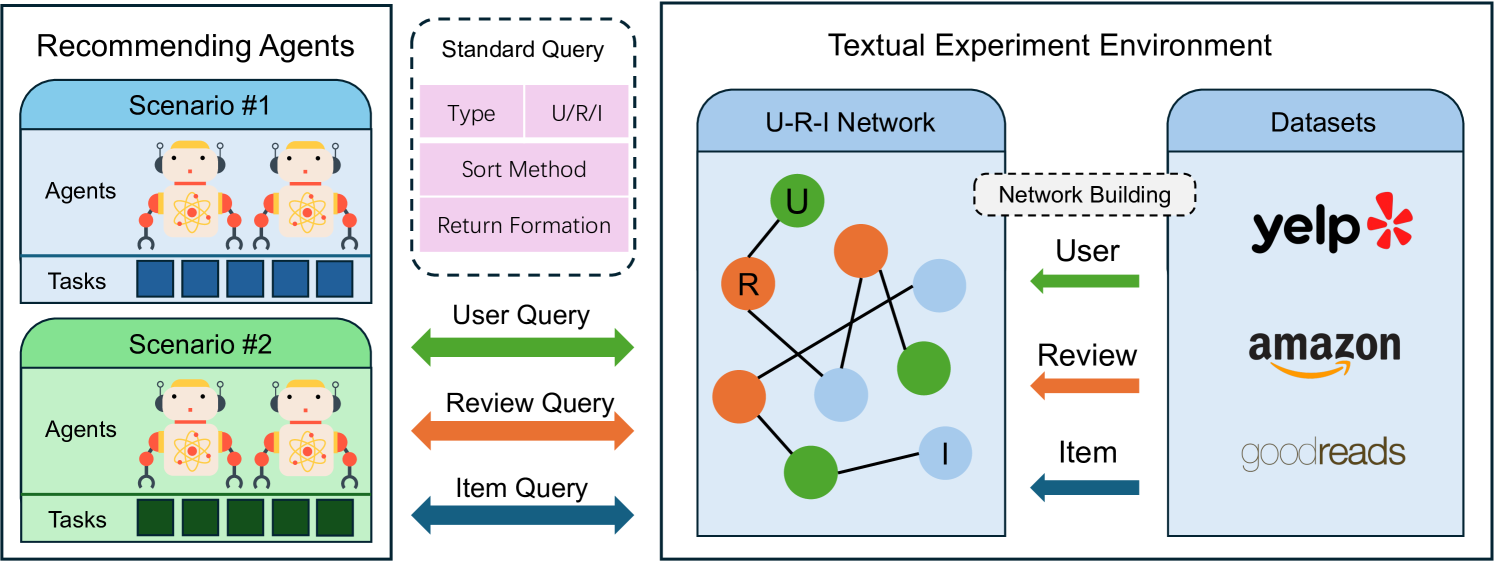
The overall framework of the Textual Environment Simulator and its interaction with the Agent.
Evaluation Highlights
- Agentic methods (e.g., Baseline666, Agent4Rec) outperform traditional Matrix Factorization by significant margins in cold-start scenarios (e.g., +0.03-0.05 HR@5 on Yelp User Cold-Start).
- In evolving-interest tasks, agentic systems demonstrate superior adaptation; specifically, Baseline666 achieves the highest performance on short-term interest modeling.
- The benchmark validated its utility through the AgentSociety Challenge, where participants achieved a 20.3% performance improvement during the development phase.
Breakthrough Assessment
9/10
Establishes the first comprehensive, standardized benchmark for the rapidly growing field of agentic recommendation. The combination of a simulator, modular framework, and rigorous scenario design fills a critical gap.