📝 Paper Summary
Session-based Recommendation (SBR)
LLM-based User Profiling
SPRINT enhances session-based recommendation by selectively invoking LLMs during training to populate a global intent pool, then training a lightweight predictor to infer these intents at inference time without LLM dependency.
Core Problem
Directly applying LLMs to session-based recommendation fails because short, anonymous sessions lack sufficient context for reliable profiling (leading to hallucinations) and per-session LLM inference is prohibitively slow.
Why it matters:
- Real-world session data is voluminous and anonymous, making the computational cost of live LLM inference impractical for deployment
- Short sessions (e.g., avg length ~3.6 on Yelp) provide too little signal for standard LLM profiling, resulting in vague or noisy descriptions that degrade recommendation accuracy
- Existing intent modeling methods lack explicit validation mechanisms to ensure generated intents actually contribute to predictive performance
Concrete Example:
A user browsing 'eco-friendly' and 'environmentally friendly' skincare might generate redundant, slightly different text profiles if processed independently by an LLM. Furthermore, on a short session with just 3 clicks, an LLM might hallucinate a 'summer necessity' intent that isn't grounded in the data, misleading the recommender.
Key Novelty
Scalable and Predictive Intent Refinement (SPRINT)
- Constrains LLM generation to a shared 'Global Intent Pool' (GIP) to ensure consistency and reduces hallucinations by treating generation as an identification task over this pool
- Selectively invokes LLMs only for 'hard' sessions (high uncertainty) during training, validating intents via a Predict-and-Correct loop where the LLM must successfully predict the next item to 'commit' an intent
- Eliminates LLM latency at inference by distilling knowledge into a lightweight 'Intent Predictor' that enriches intent labels via collaborative signals from similar sessions
Architecture
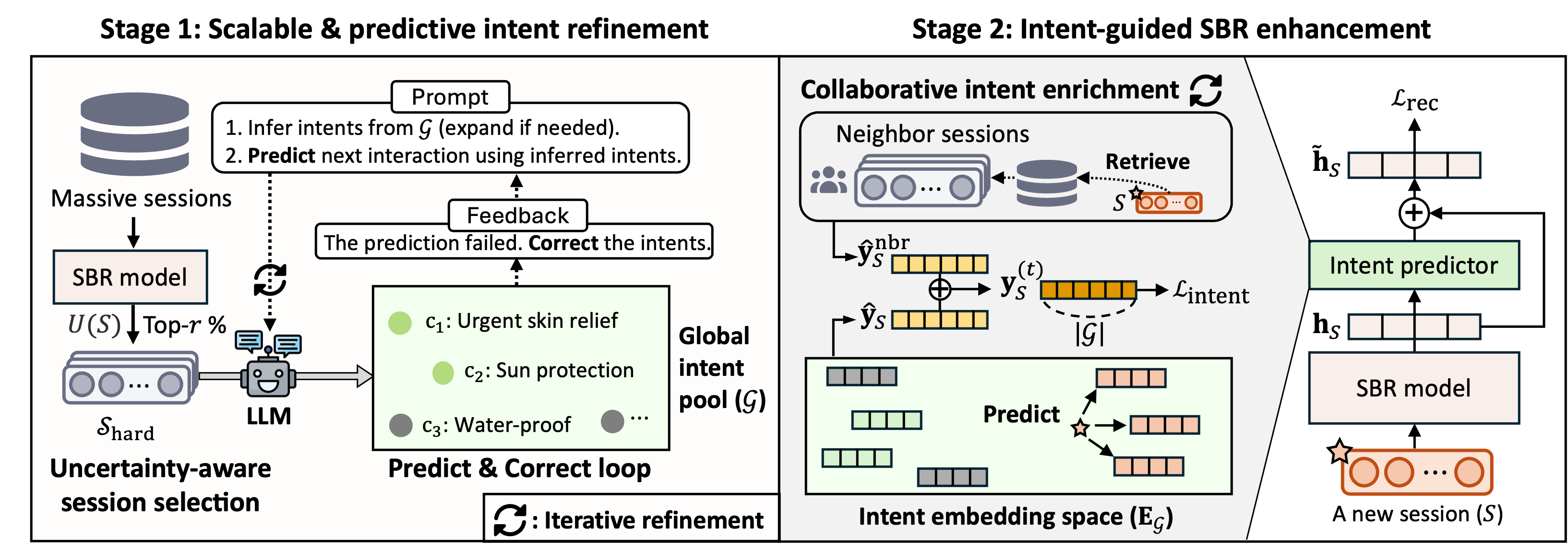
The overall SPRINT framework, illustrating the two-stage process: (1) Uncertainty-aware session selection and LLM-based intent refinement (P&C loop) to populate the Global Intent Pool, and (2) Training the SBR model with a lightweight Intent Predictor that learns from the pool.
Breakthrough Assessment
8/10
Addresses the critical bottleneck of LLM latency in recommendation by completely removing the LLM from the inference loop while still leveraging its reasoning capabilities during training.