📝 Paper Summary
LLM as Recommender System
Benchmarking
RecBench systematically evaluates 17 LLMs against conventional recommenders across varying item representations and tasks, finding LLMs superior in accuracy but significantly less efficient.
Core Problem
Existing benchmarks for LLM-based recommenders are fragmented, often evaluating single scenarios with limited item representations (mostly text/ID) and lacking comprehensive comparisons with diverse traditional models and datasets.
Why it matters:
- Industrial applications require balancing accuracy and efficiency; while LLMs show promise, their practical trade-offs against optimized conventional models remain unclear without a standardized comparison.
- Current studies often overlook diverse item representations like semantic identifiers, leading to an incomplete understanding of how best to align LLMs with recommendation tasks.
Concrete Example:
Previous benchmarks like LLMRec or PromptRec typically test only text-based or ID-based inputs on a single dataset like Amazon Beauty. They fail to reveal how an LLM performs when items are represented as hierarchical semantic codes (semantic identifiers) versus traditional IDs across diverse domains like News or Fashion.
Key Novelty
RecBench: A Multi-Dimensional Evaluation Framework
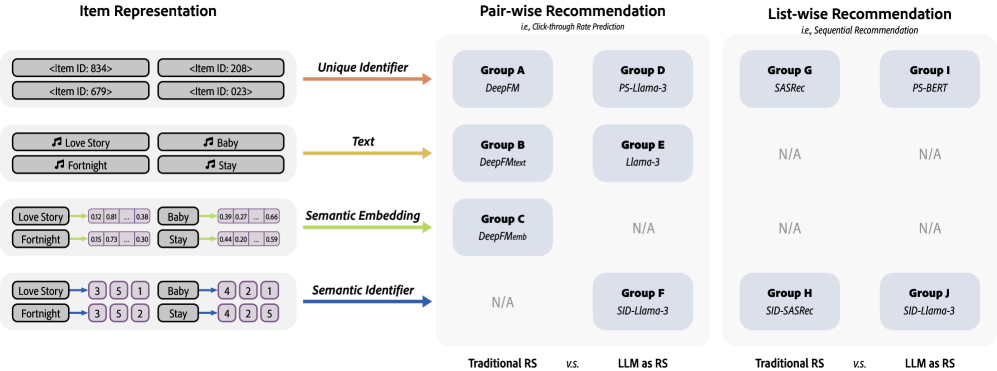
- Systematically compares four distinct item representation forms (unique identifier, text, semantic embedding, semantic identifier) to determine optimal alignment between items and LLMs.
- Evaluates both pair-wise (CTR) and list-wise (SeqRec) tasks across 5 diverse domains (Fashion, News, Video, Books, Music) using 17 different LLMs and diverse conventional baselines.
- Introduces a 'Conditional Beam Search' (CBS) for semantic identifiers to ensure generated token sequences always map to valid items in the candidate set.
Architecture
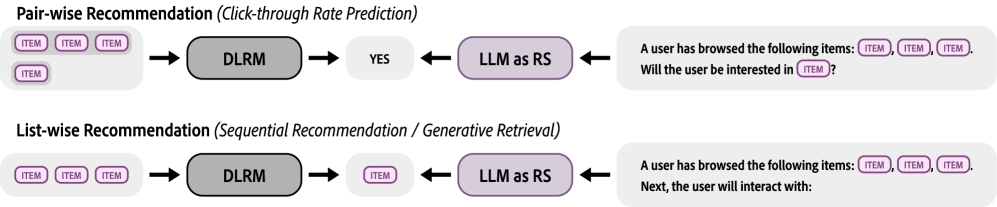
The RecBench framework illustrating the Item Representation module, the two main Recommendation Tasks (Pair-wise CTR and List-wise SeqRec), and the Evaluation protocols.
Evaluation Highlights
- LLM-based recommenders achieve up to +5% improvement in AUC for CTR prediction compared to conventional deep learning models.
- In Sequential Recommendation, LLMs outperform baselines by up to +170% in NDCG@10.
- Conventional models enhanced with LLM embeddings (LLM-for-RS) achieve 95% of the performance of standalone LLMs while maintaining significantly higher inference speed.
Breakthrough Assessment
8/10
Provides the most comprehensive and standardized benchmark to date for LLM-based recommendation, covering diverse representations and tasks, though primarily an evaluation paper rather than a new architectural proposal.