📝 Paper Summary
Recommender Systems
LLM alignment
This paper decouples novelty generation from user preference alignment by using two specialized LLMs—one for exploring new interests and one for ranking them based on collective feedback—improved via inference-time sampling.
Core Problem
Exploration in recommender systems is difficult because implicit feedback loops reinforce existing preferences, and aligning LLMs to be both novel and relevant is unstable (catastrophic forgetting or reward hacking).
Why it matters:
- Traditional collaborative filtering reinforces feedback loops, limiting users to their established interests and hurting long-term engagement
- Standard RLHF fails for exploration: reward models hack the objective (predicting popular words like 'cat' or 'BTS') and lose the ability to generate structured, diverse plans
- Balancing novelty and relevance is a competing objective; optimizing for one often degrades the other in a single model
Concrete Example:
When using standard RLHF to align a novelty-seeking LLM, the model collapsed after 5k steps: its adherence to output format dropped from >99% to 2%, and it began spamming high-reward terms like 'toys' instead of generating valid interest clusters.
Key Novelty
Decoupled Dual-LLM Exploration with Inference Scaling
- Separates the problem into two models: a 'Novelty Model' (policy) that generates diverse candidate interests, and an 'Alignment Model' (reward) trained on collective user feedback to score them
- Uses inference-time scaling (generating many candidates at high temperature) to find options that satisfy both novelty and relevance, rather than forcing one model to learn both simultaneously
Architecture
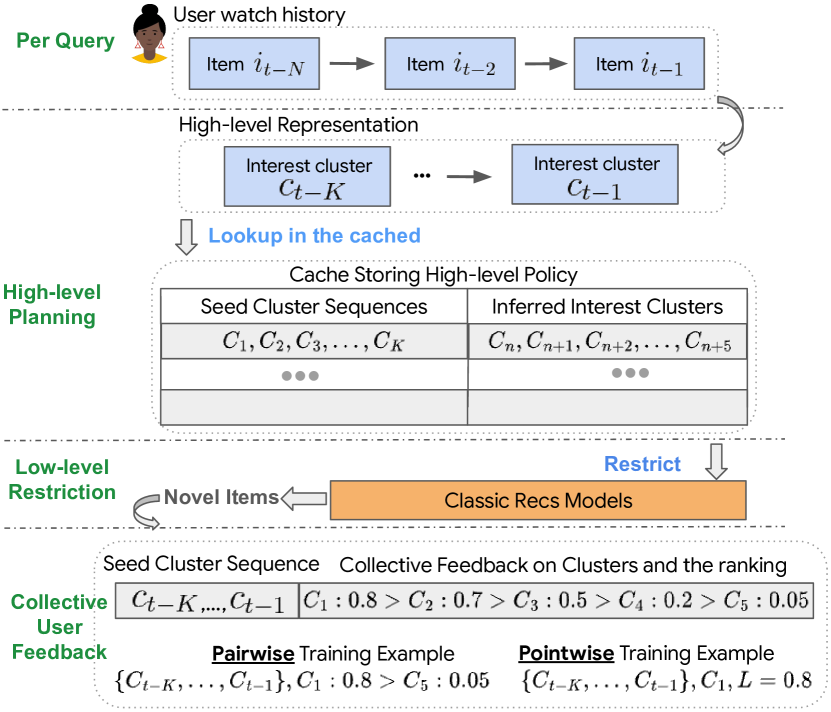
The Hierarchical Planning Paradigm. It illustrates the flow from User History -> LLM Novelty Prediction -> Novel Interest Clusters -> Backbone Recommender -> Final Items.
Evaluation Highlights
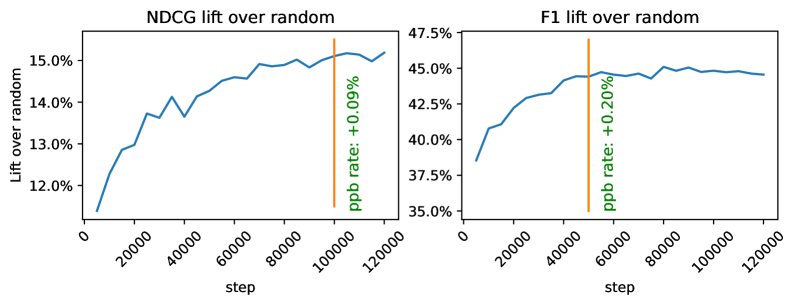
- Significant gains in user satisfaction (measured by watch activity) and active user counts in live experiments on a platform with billions of users
- Improved offline ranking metrics (F1@K and NDCG@K) against ground-truth user feedback compared to random baselines
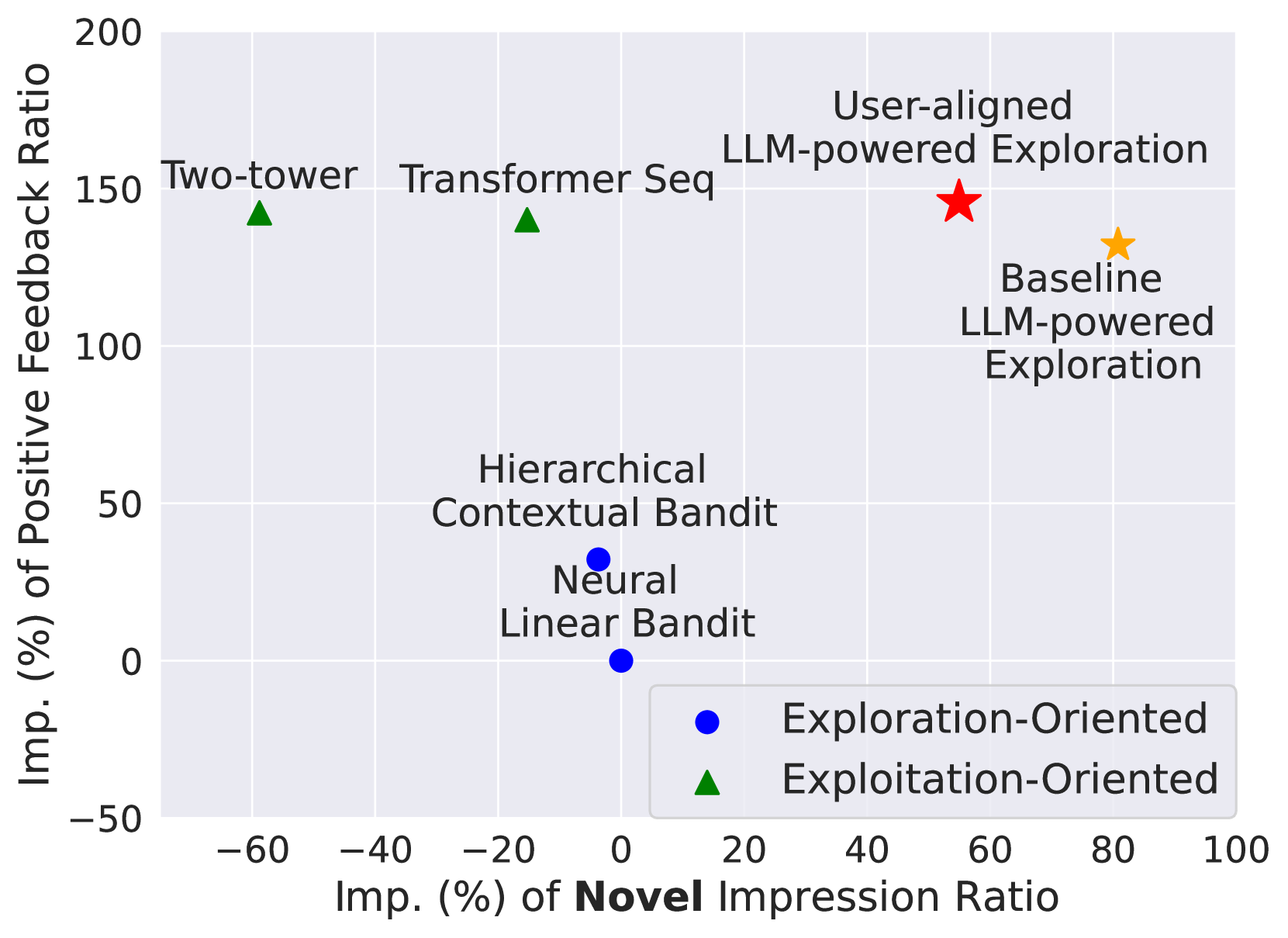
- Outperforms production baselines including hierarchical contextual bandits and neural linear bandits in both novelty and quality metrics
Breakthrough Assessment
8/10
Highly practical solution deployed at massive scale (YouTube). Effectively solves the 'reward hacking' problem in RLHF for recommendation by decoupling generation and evaluation.