📝 Paper Summary
LLM-based Recommender Systems
Benchmark Construction
RecBench+ is a benchmark dataset comprising approximately 30,000 complex, conversational queries designed to evaluate Large Language Models' ability to reason and act as personalized recommendation assistants.
Core Problem
Traditional recommender evaluations rely on simple ID-based tasks or rigid prompt templates (e.g., 'Will user like X?'), which fail to test the reasoning and conversational capabilities required for intelligent recommendation assistants.
Why it matters:
- Real-world users have complex needs involving multi-hop reasoning (e.g., 'movies by the cinematographer of X') that simple ID matching cannot capture
- Existing datasets like MovieLens lack high-quality textual queries, limiting the development of interactive LLM-based assistants
- Current evaluation paradigms relying on fixed templates do not assess an agent's ability to handle misleading information or implicit user preferences
Concrete Example:
A user asks, 'Recommend movies with the same cinematographer as Stay Hungry.' A traditional model only sees user-item IDs and fails. An LLM assistant must infer the cinematographer (David Worth) and find related items, a capability not tested by current benchmarks.
Key Novelty
RecBench+: A Knowledge Graph-Grounded Benchmark for Complex Recommendation
- Categorizes user needs into Condition-based (explicit, implicit, misinformed) and User Profile-based (interest, demographics) queries to test diverse reasoning levels
- Leverages Knowledge Graphs (KG) to extract shared relations from user history, ensuring ground-truth accuracy for complex constraints before generating natural language queries
Architecture
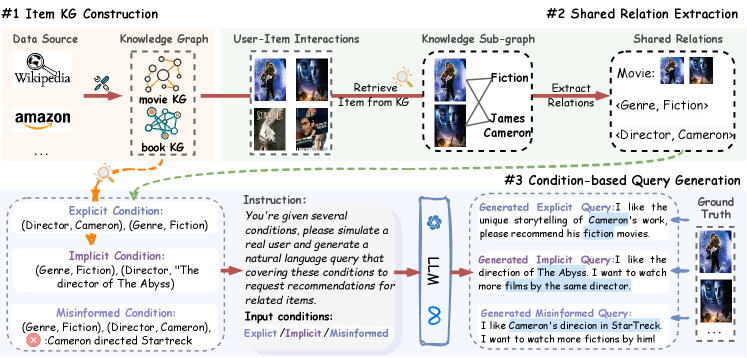
The data construction pipeline for Condition-based Queries using a Knowledge Graph
Evaluation Highlights
- Evaluation of 7 LLMs reveals that models perform better on explicitly stated conditions than on queries requiring multi-hop reasoning or correction of misleading info
- Fine-tuning (Supervised + Reinforcement) notably improves performance, with a two-stage approach outperforming SFT alone
- Models show demographic performance variance, generally performing better for female users and popular interests
Breakthrough Assessment
8/10
Addresses a critical gap in evaluating LLM-based recommenders by moving beyond ID prediction to complex reasoning. The construction methodology using KGs for ground truth is robust.