📝 Paper Summary
LLM-based Recommendation
Evaluation Frameworks
This paper proposes a multidimensional framework to evaluate LLM recommenders, focusing on unique LLM behaviors like position bias, hallucination, and history sensitivity alongside traditional accuracy.
Core Problem
Existing evaluations of LLM-based recommenders focus primarily on utility (accuracy) and standard metrics, ignoring LLM-specific failure modes and biases.
Why it matters:
- LLMs exhibit unique behaviors unknown to traditional models, such as recommending non-existent items (hallucination) or favoring items based on input order (position bias)
- Traditional metrics like accuracy do not capture the generative and textual capabilities of LLMs, such as the ability to generate interpretable user profiles
- Ignoring these dimensions can lead to deployed systems that seem accurate but provide poor user experience due to bias or fabrication
Concrete Example:
An LLM recommender might achieve high accuracy on a benchmark but systematically prefer items placed at the top of the input list regardless of relevance (position bias), or it might recommend a movie title that sounds plausible but does not actually exist (hallucination).
Key Novelty
Multidimensional Evaluation Framework for LLM-as-Recommender
- Introduces four new evaluation dimensions specifically for LLMs: history length sensitivity, candidate position bias, generation-involved performance (profiling), and hallucinations
- Adapts evaluation for both ranking and re-ranking tasks, using a small-sample testing strategy with statistical verification (K-S test) to manage LLM inference costs
Architecture
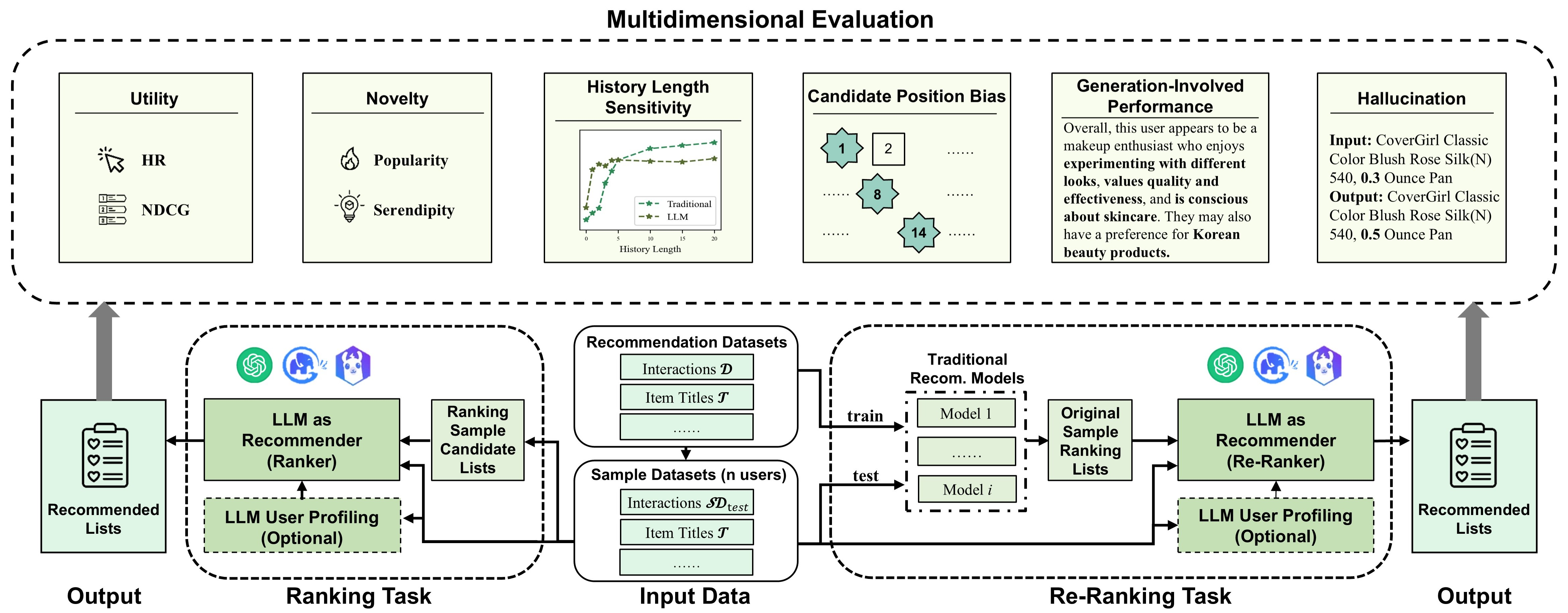
Overview of the multidimensional evaluation framework
Breakthrough Assessment
7/10
Provides a necessary and comprehensive framework for evaluating the specific quirks of LLM recommenders, moving beyond simple accuracy leaderboards, though the core contribution is evaluation methodology rather than a new model architecture.