📝 Paper Summary
Privacy in Recommender Systems
LLM Inversion Attacks
Adversarial Machine Learning
This paper demonstrates that sensitive user interaction histories and demographics in LLM-powered recommender systems can be reconstructed from output logits using an inversion attack enhanced by similarity-guided refinement.
Core Problem
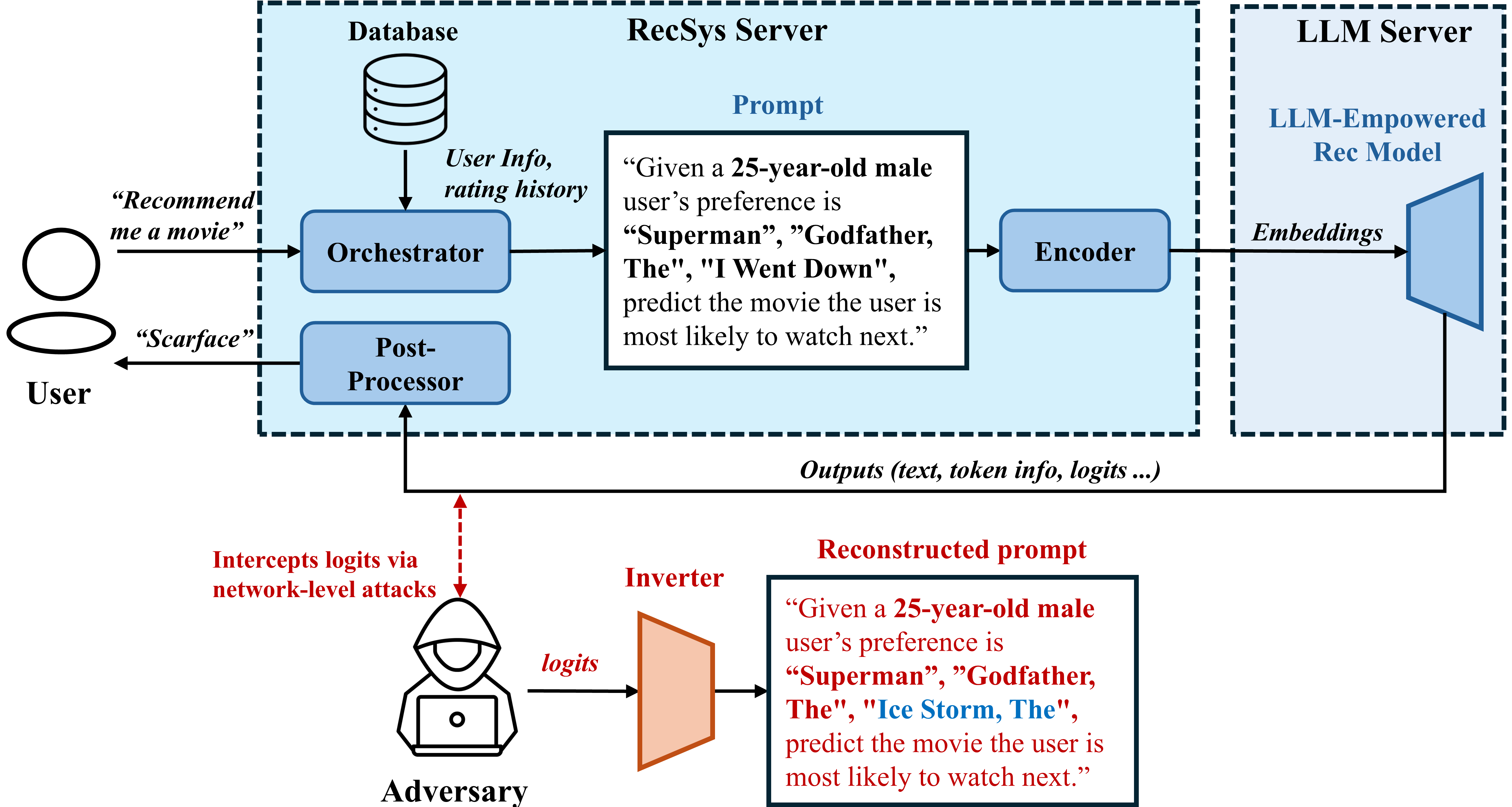
LLM-empowered recommender systems (RecSys) construct highly sensitive prompts containing user history and profiles, but exposing the model's output logits allows adversaries to reconstruct this private information.
Why it matters:
- LLM-RecSys explicitly incorporate detailed personal data (history, age, gender) into prompts, making leaks far more severe than in traditional ID-based systems
- Standard inversion attacks focus on general text generation; RecSys tasks often yield sparse text (e.g., 'Yes/No') but rich logits, requiring specialized attack methods
- Malicious users or eavesdroppers can uncover proprietary system instructions and private user data simply by analyzing the probability distributions of the system's responses
Concrete Example:
A user prompt might be 'The user is a 25-year-old male who liked Matrix and Inception...'. The RecSys outputs logits for a binary prediction (Like/Dislike). An attacker captures these logits and uses the proposed inversion model to regenerate the original text: 'User: 25 male, History: Matrix, Inception'.
Key Novelty
Similarity-Guided Refinement for RecSys Inversion
- Adapts the vec2text framework to the recommendation domain by training on a novel synthetic dataset of diverse RecSys prompt templates
- Introduces an iterative refinement loop: the attacker generates candidate prompts, feeds them back into the victim model to get logits, and selects the candidate whose logits are most similar (cosine similarity) to the original observed logits
Architecture
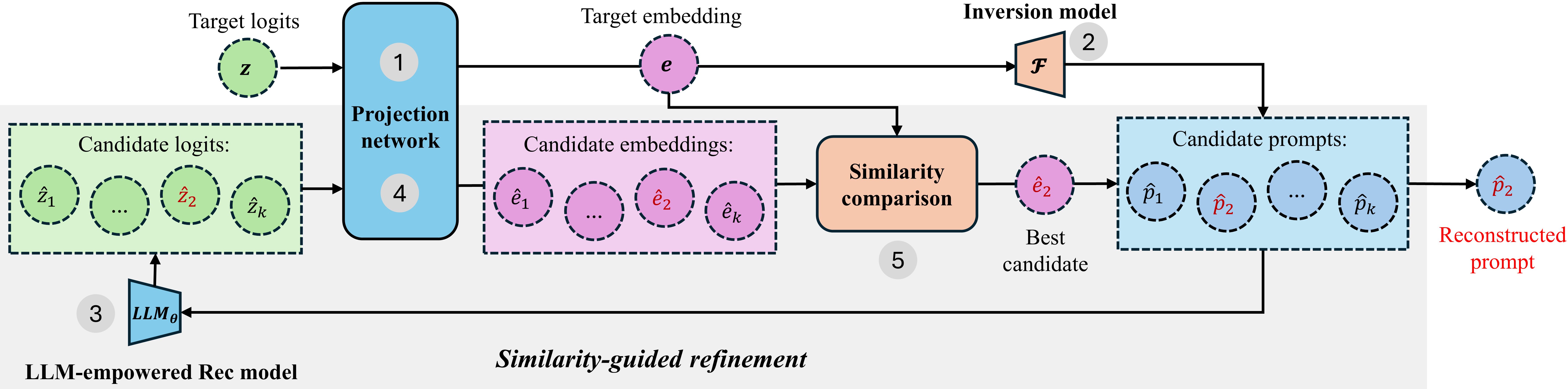
The proposed inversion framework pipeline
Evaluation Highlights
- Reconstructs nearly 65% of user-interacted item titles from the output logits of LLM-based recommenders
- Correctly infers sensitive demographic attributes (age and gender) in 87% of cases
- Proposed similarity-guided refinement strategy yields an additional 5–13% improvement in reconstruction fidelity over the base inversion model
Breakthrough Assessment
8/10
First systematic study exposing privacy risks in LLM-RecSys via inversion. The results (87% demographic inference) are alarmingly high and highlight a critical vulnerability in a growing field.