📝 Paper Summary
LLM Reasoning for Personalization
Evaluation of Subjective Reasoning
The paper leverages Chain-of-Thought prompting to enhance personalized rating predictions and introduces Rec-SAVER, a framework to automatically evaluate the quality of subjective reasoning without human-curated gold references.
Core Problem
Applying LLM reasoning to recommender systems is difficult because user preferences are subjective (unlike math problems with definitive answers), making it hard to obtain gold-standard reasoning chains for training or evaluation.
Why it matters:
- Subjectivity in personalization is an under-explored domain for LLM reasoning compared to objective tasks like arithmetic or commonsense QA.
- Evaluating the quality of LLM-generated explanations is impossible without curated gold references, which are unavailable for personalized user behavior.
- Standard metrics do not capture whether a reasoning chain is faithful or coherent with a user's specific history.
Concrete Example:
In arithmetic, '2+2=4' is a clear gold standard. In RecSys, predicting why a user rated a movie 5 stars is subjective; the user might like the genre or the actor. Without a 'gold' reason, we cannot easily verify if an LLM's explanation ('User likes sci-fi') is correct or hallucinated.
Key Novelty
Rec-SAVER (Recommender Systems Automatic Verification and Evaluation of Reasoning)
- A self-verification framework where an LLM first generates a post-hoc explanation for a rating, then tries to predict the rating solely based on that explanation (masking the answer).
- If the explanation allows the model to reproduce the correct ground-truth rating, the explanation is deemed a 'verified reference' and used to evaluate other models.
Architecture
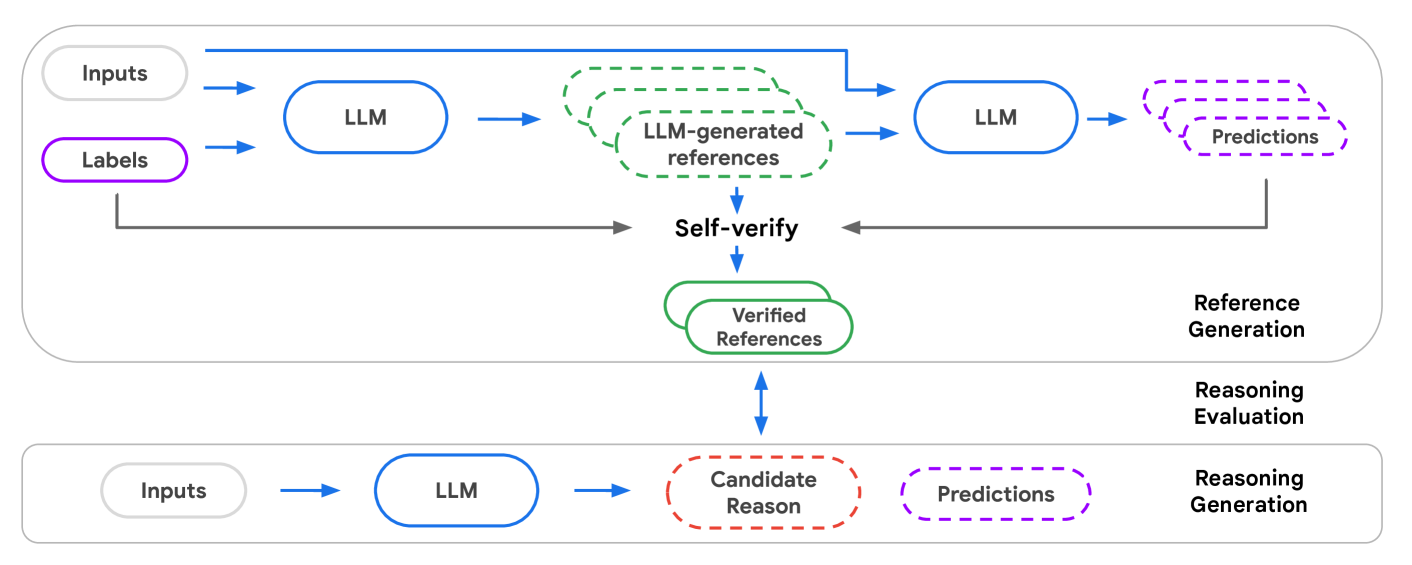
The Rec-SAVER evaluation framework pipeline
Evaluation Highlights
- Syntactic metrics (BLEU, ROUGE) align with human judgment when evaluating the faithfulness of reasoning outputs.
- Embedding-based metrics (METEOR, BERTScore) align with human judgment when measuring the coherence of generated reasoning.
Breakthrough Assessment
7/10
Addresses a critical bottleneck in applying LLMs to RecSys (lack of reasoning ground truth). The Rec-SAVER self-verification loop is a clever, domain-agnostic solution for subjective evaluation.