📝 Paper Summary
LLM-based Recommendation
Multimodal Alignment
Prompt Tuning
RA-Rec aligns pre-trained recommender ID embeddings with frozen LLMs via a lightweight projection module, combining collaborative signals with language reasoning without expensive full-model fine-tuning.
Core Problem
Existing LLM-based recommendation methods either use raw IDs (lacking semantics) or translate IDs to text (hitting token limits and losing collaborative signals), failing to effectively bridge collaborative data with language models.
Why it matters:
- Raw ID numbers carry no inherent meaning for LLMs, leading to poor generalization
- Translating interaction histories into text titles (e.g., 'shoes', 'dress') consumes excessive token context, preventing the modeling of long-term user behavior
- Directly fine-tuning LLMs on large-scale recommendation data is computationally prohibitive and risks catastrophic forgetting of general knowledge
Concrete Example:
In the 'ID Direct' paradigm, an LLM sees 'User 15 bought 115, 301' and cannot infer meaning. In 'ID Translation', a long history becomes a massive text block exceeding the context window (e.g., 2048 tokens). RA-Rec injects the compact vector representation of 'Item 115' directly as a soft prompt, preserving collaborative information within the LLM's capacity.
Key Novelty
ID Representation Alignment Paradigm
- Treats pre-trained ID embeddings (from traditional recommenders) as 'soft prompts' that provide implicit collaborative knowledge to the LLM
- Uses a 'reparameterization' module to project ID embeddings into the LLM's latent space, tailored to specific transformer layers
- Introduces 'contextual instructions' (learnable vector prefixes) to guide the LLM on how to utilize the injected ID information
Architecture
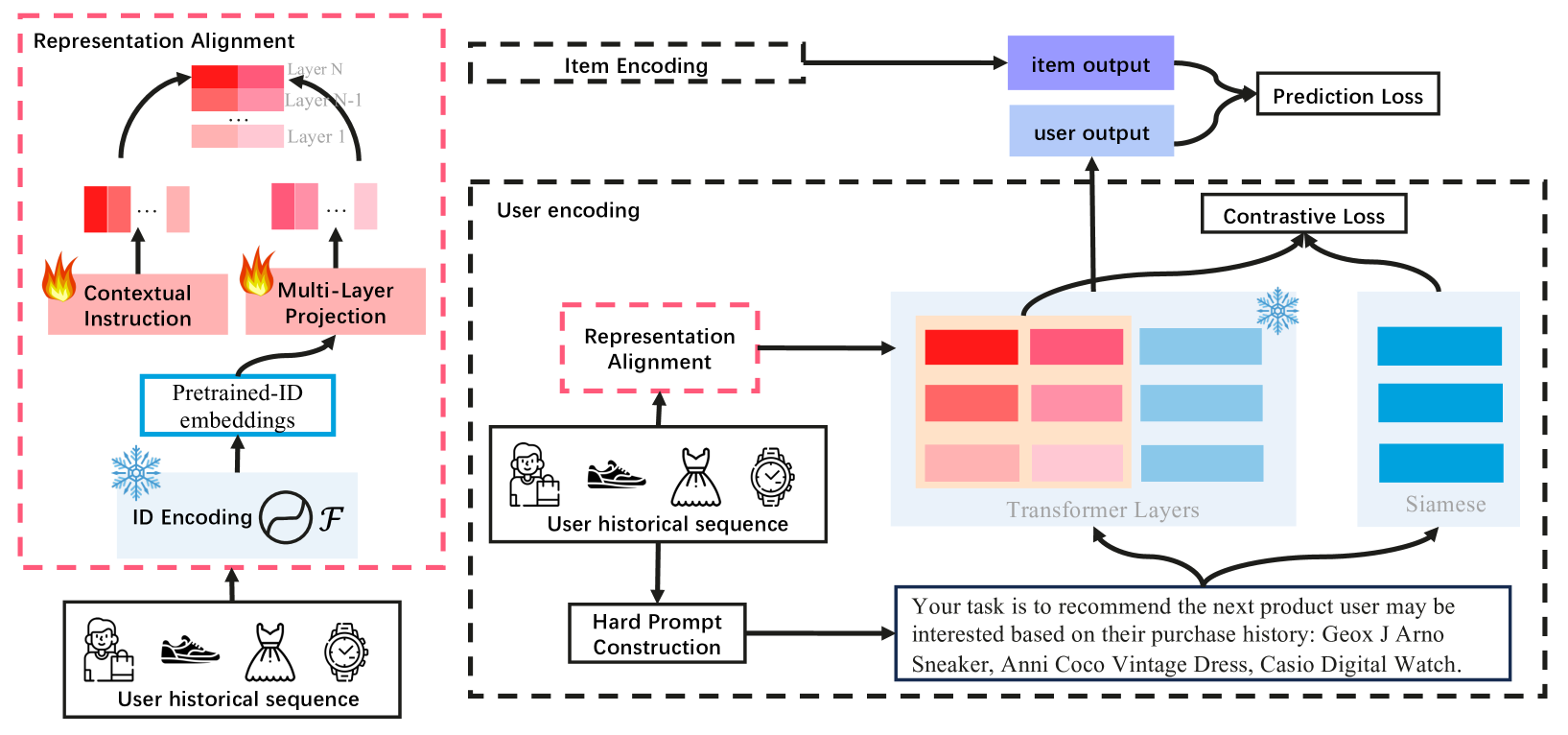
The overall RA-Rec framework, illustrating how ID embeddings and text prompts are processed and aligned.
Evaluation Highlights
- Improves HitRate@100 by 25.9% relative to baselines on the Amazon Cloth dataset
- Achieves up to 3.0% absolute HitRate@100 improvement while using less than 10x the training data compared to baselines
- Improves NDCG@10 by 15.1% relative to baselines on the Amazon Book dataset
Breakthrough Assessment
7/10
Proposes a logical third paradigm (Alignment) effectively bridging the gap between ID-based and Text-based recommendation. Strong efficiency claims, though evaluation is on standard datasets.