📝 Paper Summary
Multi-Scenario Recommendation (MSR)
LLM-Enhanced Recommendation
LLM4MSR leverages a frozen LLM to reason about user and scenario semantics, then uses hierarchical meta-networks to generate adaptive weights that enhance a multi-scenario recommendation backbone.
Core Problem
Existing Multi-Scenario Recommendation (MSR) methods rely heavily on simple domain indicators and collaborative signals, ignoring rich semantic scenario knowledge and personalized cross-scenario preferences.
Why it matters:
- Insufficient scenario knowledge (e.g., relying only on ID) leads to poor correlation modeling between diverse business domains
- Directly deploying LLMs in industrial systems is hindered by high inference latency and tuning costs
- Current methods fail to disentangle and explicitly model users' personalized interests across different scenarios
Concrete Example:
In an app with 'search' and 'recommendation' scenarios, standard models distinguish them only by a domain ID. They fail to understand that a user's positive interaction with 'electronics' in 'search' semantically implies a specific interest that should transfer to 'recommendation' differently than a random click.
Key Novelty
LLM-Driven Hierarchical Meta-Network Injection
- Uses a frozen LLM not as a feature extractor or ranker, but as a 'reasoner' that outputs a high-dimensional hidden state encapsulating scenario and user semantics
- This hidden state drives 'meta-networks' that dynamically generate the weights and biases (meta layers) for the recommendation backbone, effectively modulating the backbone with semantic knowledge
- Adopts a hierarchical structure where user-level knowledge modulates bottom layers and scenario-level knowledge modulates parallel layers
Architecture
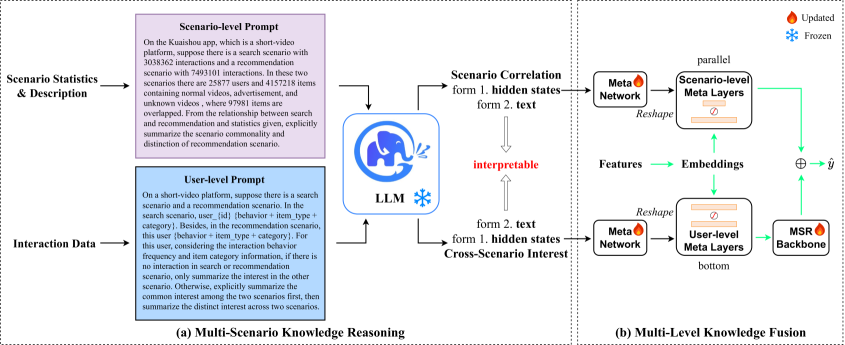
The overall architecture of LLM4MSR, detailing the prompt construction, LLM reasoning, and hierarchical meta-network injection into the backbone.
Breakthrough Assessment
8/10
Proposes a novel paradigm of using LLMs to generate parameters (meta-learning) rather than just features or text, solving the efficiency bottleneck while injecting semantic intelligence.