📝 Paper Summary
LLM-based Recommendation
Parameter-Efficient Fine-Tuning (PEFT)
Domain Adaptation
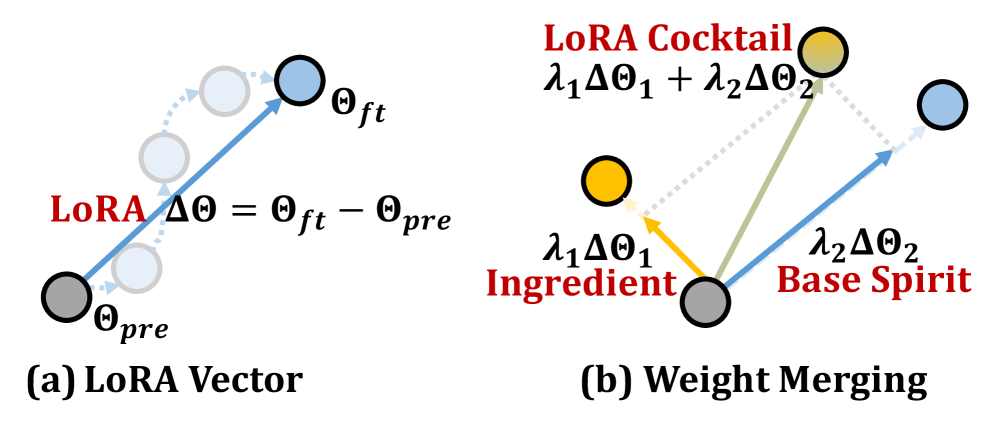
RecCocktail merges a general-purpose recommendation LoRA module with a domain-specific LoRA module via linear weight arithmetic to achieve both generalization and domain adaptability without extra inference cost.
Core Problem
Current LLM-based recommenders typically focus on either breadth (generalization via multi-domain data) or depth (domain-specific tuning), failing to simultaneously handle new domains and maximize performance on specific ones.
Why it matters:
- Breadth-oriented models often underperform in specific domains due to lack of deep alignment.
- Depth-oriented models struggle with distribution shifts, cold-start scenarios, and new domains where training data is sparse.
- Existing solutions like ensembling outputs increase inference latency, while sequential fine-tuning risks catastrophic forgetting.
Concrete Example:
A model trained on general e-commerce data might understand shopping but fail to capture the specific nuances of 'MovieLens' user behavior. Conversely, a model fine-tuned only on MovieLens fails completely when transferred to a new 'Toys' domain without retraining.
Key Novelty
LoRA Cocktail (Weight Space Merging)
- Treats LoRA adapters as 'task vectors' that can be linearly combined in weight space, merging a 'base spirit' (general knowledge) and an 'ingredient' (domain-specific knowledge).
- Introduces an entropy-guided adaptive merging strategy that tunes the mixing coefficients at test time using unlabeled data to minimize prediction uncertainty.
Architecture
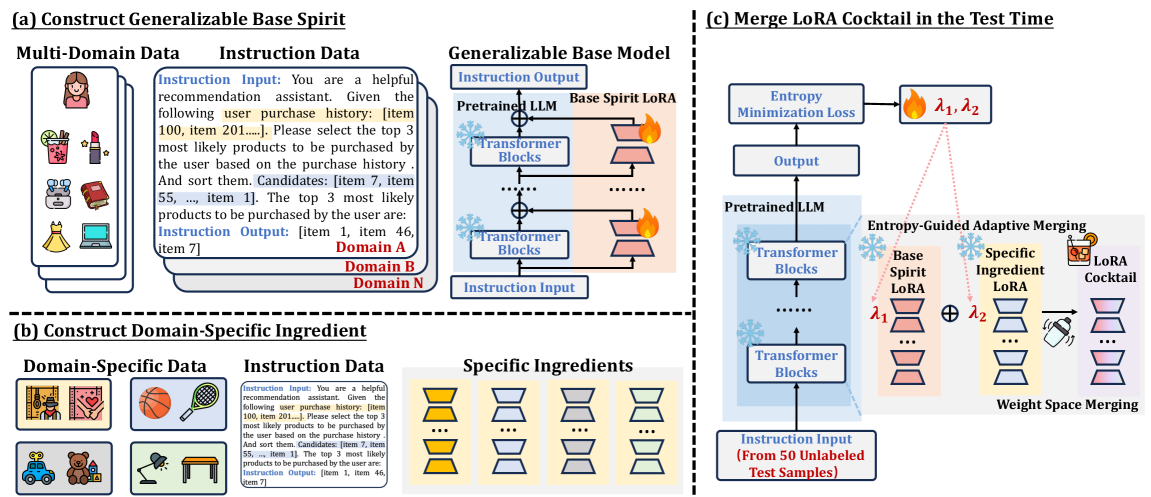
The three-stage framework of RecCocktail: (a) Preparing Base Spirit via general instruction tuning, (b) Preparing Ingredient via domain-specific tuning, and (c) Making Cocktail via entropy-guided weight merging.
Evaluation Highlights
- Outperforms state-of-the-art LLM-based methods (TALLRec, AlphaRec) by significant margins on MovieLens-1M (NDCG@1: 0.5783 vs 0.5392 for TALLRec).
- Achieves consistent gains across four datasets (Beauty, Toys, Sports, MovieLens), improving NDCG@1 by ~7-20% over strong baselines.
- Demonstrates robust generalization: The general 'base spirit' module alone often outperforms zero-shot LLMs and some traditional methods even without domain-specific tuning.
Breakthrough Assessment
8/10
Elegantly solves the dilemma between generalization and specialization in LLM-Rec via simple weight arithmetic. The entropy-guided merging makes it adaptive without retraining, offering high practical value.