📝 Paper Summary
Federated Learning for Recommendation (Fed4Rec)
LLM-based Recommendation
FELLRec adapts federated learning for LLM-based recommendation by using dynamic, attention-based aggregation to balance client performance and offloading non-sensitive layers to the server to reduce client resource costs.
Core Problem
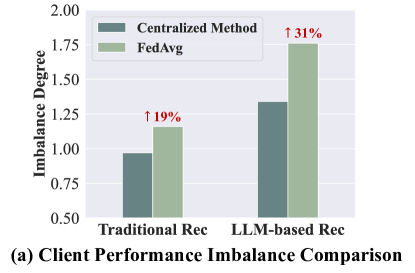
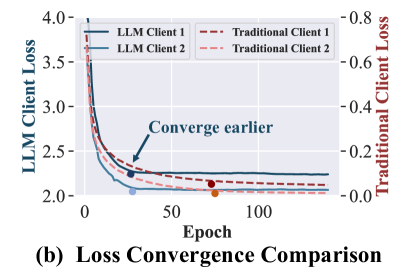
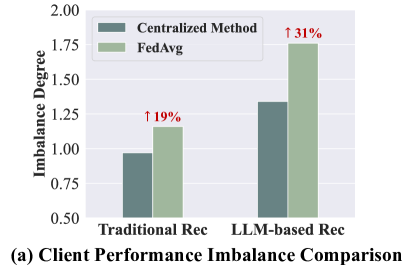
Directly applying federated learning to LLM-based recommendation exacerbates performance imbalance across clients (due to diverse data distributions and convergence speeds) and imposes prohibitive computational/storage costs on individual clients.
Why it matters:
- Standard federated averaging (FedAvg) treats all clients equally, ignoring that some clients struggle with harder data distributions or slower convergence, leading to poor long-term fairness
- Running full LLMs on user devices (clients) is often unfeasible due to memory and compute constraints
- Centralized fine-tuning of LLMs on user behavior data risks leaking sensitive private information, violating regulations like GDPR
Concrete Example:
In a standard FedAvg setup, a client with unique or sparse interaction history might have their specific preferences overwritten by the global model average, leading to worse recommendations than a local-only model. Additionally, a mobile client cannot store a full 7B parameter model for local training.
Key Novelty
Federated Framework for LLM-based Recommendation (FELLRec)
- Dynamic Balance Strategy: Adjusts how much each client learns from others based on data similarity (attention mechanism) and regulates learning speed based on local loss (curriculum heating), preventing negative transfer.
- Flexible Storage Strategy: Splits the LLM so clients only store/compute sensitive input/output layers locally, offloading the bulk of intermediate heavy computation to the server without exposing raw user data.
Architecture
The overall architecture of FELLRec, illustrating the Client-Server split and the dynamic aggregation mechanism.
Evaluation Highlights
- Outperforms FedAvg by significant margins (e.g., +41.97% NDCG@5 on MovieLens-1M with Llama-2-7B) while maintaining privacy
- Reduces client storage cost by ~28% and training time by ~48% compared to standard local training when offloading intermediate layers
- Achieves more equitable performance across clients compared to FedAvg, reducing the variance in client-specific accuracy
Breakthrough Assessment
7/10
Solidly addresses two critical bottlenecks for Federated LLMs (imbalance and resource cost) with practical engineering solutions. The split-processing approach for privacy is a known technique but applied effectively here.