📝 Paper Summary
News Recommendation
Knowledge Graphs (KG)
Large Language Models (LLM)
LKPNR improves news recommendation by combining traditional encoders with LLMs for deep semantic understanding and Knowledge Graphs for collaborative entity connections, addressing sparse data issues for inactive users.
Core Problem
Traditional news recommendation models struggle with complex semantic understanding of news text and fail to effectively recommend for inactive users (the 'long tail problem') due to insufficient historical data.
Why it matters:
- Existing methods rely heavily on rich historical behaviors, leaving inactive users with poor recommendations
- Traditional text encoders (CNN/LSTM) often miss complex semantic nuances and external knowledge connections in news articles
- The 'long tail problem' means a vast majority of less popular news items are rarely recommended, reducing diversity and system effectiveness
Concrete Example:
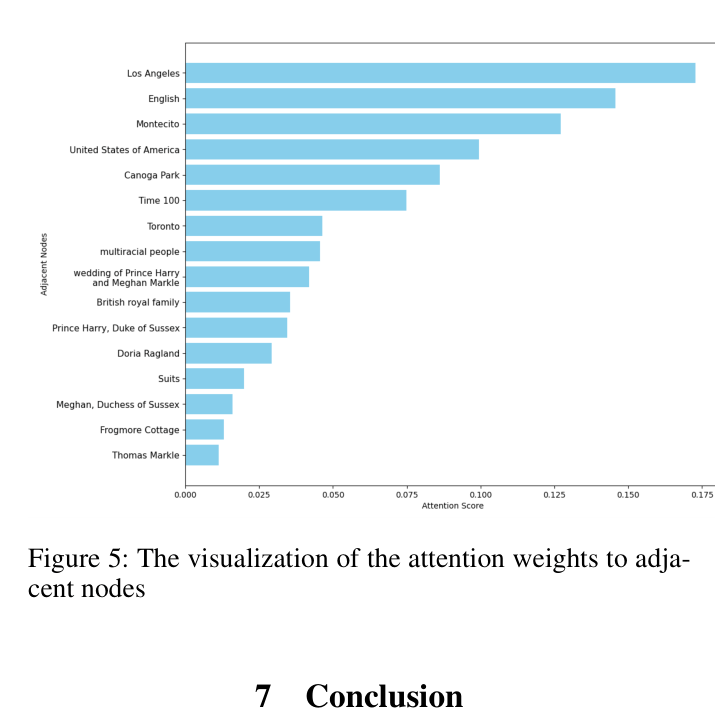
A user clicks a few news items about specific entities (e.g., 'Warriors'). A traditional model might fail to recommend a relevant but less popular article about 'D'Angelo Russell' if the user hasn't clicked it before. LKPNR uses the KG to link 'Warriors' to 'D'Angelo Russell' (a team member) and the LLM to understand the trade context, surfacing the relevant article even without direct click history.
Key Novelty
LLM and KG Augmented Personalized News Recommendation (LKPNR)
- Augments standard news encoders by running news text through an LLM to extract deep semantic representations (hidden states)
- Constructs a Knowledge Graph subgraph for entities in the news, using multi-hop neighbors to capture latent connections between seemingly unrelated news items
- Fuses three distinct representations: the general encoder's output, the LLM's semantic vector, and the KG's structural entity vector
Architecture
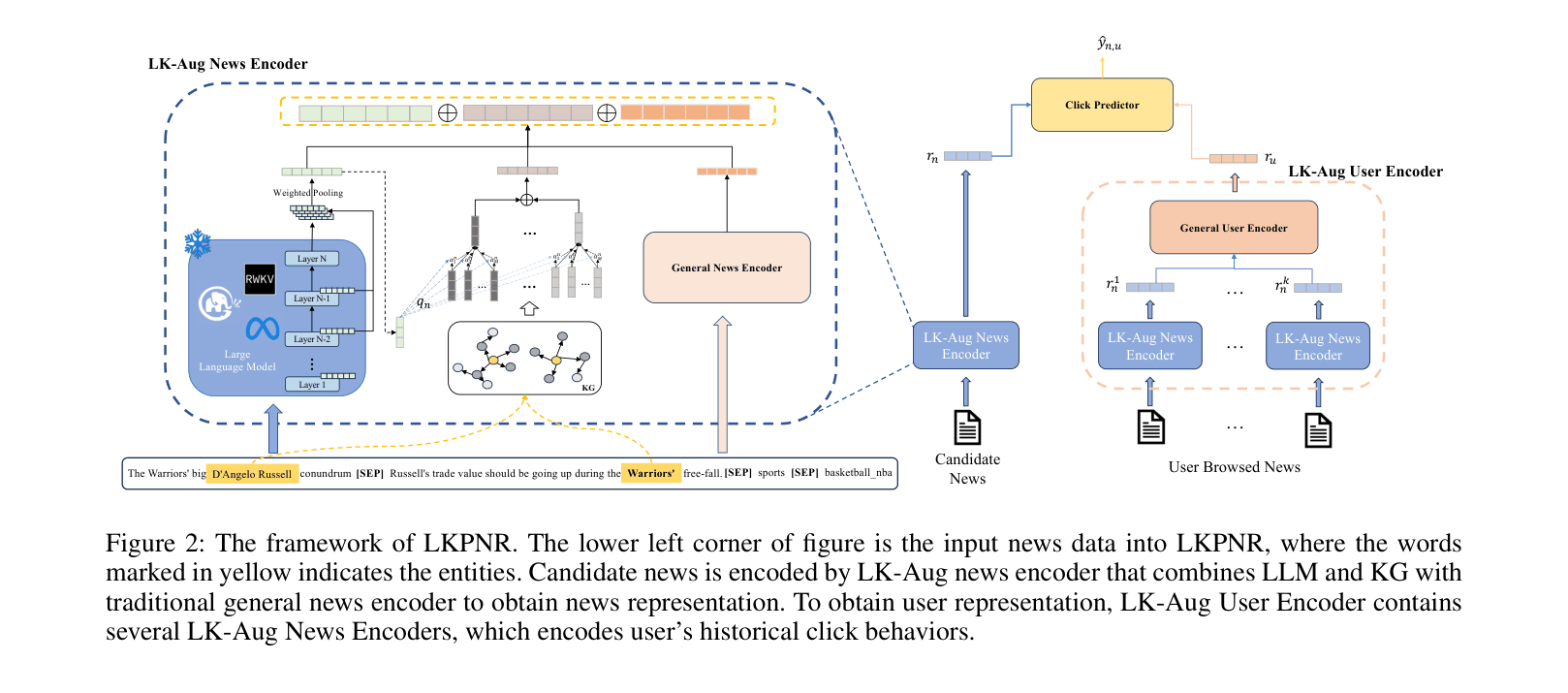
The complete LKPNR framework. Bottom left shows input news. Center shows the three encoders (General, KG, LLM) producing vectors r_GNE, r_KG, r_LLM. Right side shows user history encoding and click prediction.
Evaluation Highlights
- +2.47% AUC improvement over the NRMS baseline on the MIND dataset
- +2.25% nDCG@5 improvement over the NRMS baseline
- ChatGLM2-6B outperforms larger models like LLAMA2-13B in this framework, likely due to better alignment with the data distribution
Breakthrough Assessment
6/10
Solid integration of two trending technologies (LLM + KG) into established baselines with clear empirical gains. While the architecture is a logical extension rather than a paradigm shift, it effectively addresses the specific problem of semantic sparsity.