📝 Paper Summary
Explainable Recommender Systems
LLM-augmented Recommendation
Sequential Recommendation
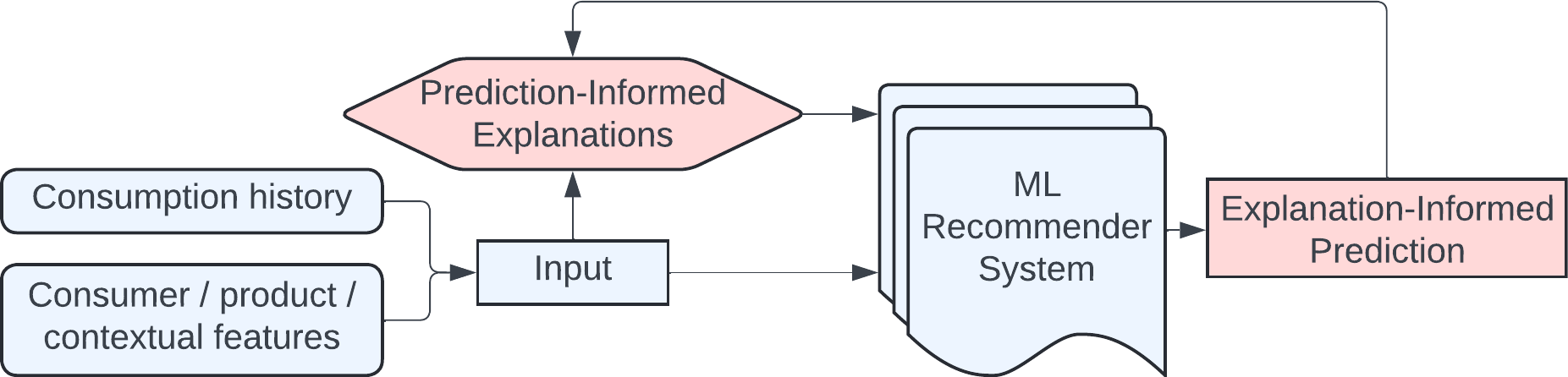
RecPIE jointly trains a generative LLM to produce explanations and a discriminative recommender to use them, using recommendation accuracy as a reward signal to ground the LLM's reasoning.
Core Problem
Existing explainable recommender systems either produce explanations that don't improve accuracy (post-hoc) or sacrifice accuracy for interpretability (white-box), while LLMs hallucinate when generating personalized explanations without ground truth.
Why it matters:
- Improving recommendation accuracy by even 0.1% yields massive economic value, but current black-box models are data-hungry and hit performance plateaus.
- LLMs offer reasoning capabilities that could improve data efficiency, but their generative nature is misaligned with the discriminative task of ranking items.
- Without ground-truth explanations for user behavior, it is difficult to train LLMs to generate useful insights rather than plausible-sounding hallucinations.
Concrete Example:
In a POI recommendation setting, a standard model might recommend a coffee shop based solely on co-visitation statistics. An ungrounded LLM might hallucinate that the user 'loves dark roasts' without evidence. RecPIE learns that explaining 'user prefers quiet places for work' leads to better predictions of future visits, reinforcing that specific explanation.
Key Novelty
RecPIE (Recommendation with Prediction-Informed Explanations)
- Establishes a bidirectional loop: The LLM generates explanations to help the recommender, and the recommender's accuracy serves as a reward signal to fine-tune the LLM.
- Uses Reinforcement Learning (PPO) to align the generative LLM with the discriminative recommendation task, treating useful explanations as those that maximize prediction accuracy.
- Injects LLM-generated explanations back into the deep neural recommender's latent space to refine user and item representations.
Architecture
Conceptual diagram of the RecPIE framework.
Evaluation Highlights
- Improves POI prediction accuracy by 3–4% over state-of-the-art baselines on Google Maps data.
- Matches the best baseline's performance using only 12% of the training data, demonstrating superior data efficiency.
- Human evaluators preferred RecPIE's explanations 61.5% of the time compared to 16.6% for the second-best method.
Breakthrough Assessment
8/10
Strong methodological contribution by successfully closing the loop between explanation generation and model improvement, with significant empirical gains in both accuracy and human-perceived quality.