📝 Paper Summary
LLM-enhanced Recommendation
Cold-start Recommendation
Knowledge Distillation
S-LLMR improves recommendation accuracy by using a learnable gating mechanism to selectively apply LLM-derived ranking supervision only where the LLM is predicted to be reliable.
Core Problem
Global distillation methods force recommenders to imitate LLM predictions uniformly, hurting performance because LLMs are not reliable across all user-item contexts.
Why it matters:
- Standalone LLM recommenders are too expensive and prone to position bias and hallucination for large-scale deployment
- Standard knowledge distillation transfers noise when the teacher (LLM) is inaccurate, degrading the student model's performance in dense data regimes where it already excels
- Traditional recommenders fail significantly on sparse data (cold-start users, long-tail items) where LLM semantic reasoning is most needed
Concrete Example:
An LLM might excel at reasoning about a cold-start user with only 3 history items based on semantics, but hallucinate or show bias for a heavy user with 100+ items where collaborative filtering is stronger. Global distillation forces the model to mimic the LLM even in the second case, harming accuracy.
Key Novelty
Selective LLM-Guided Regularization (S-LLMR)
- Treats LLM outputs as a conditional regularizer rather than a ground-truth target, using a lightweight gating network to decide 'when to trust the LLM'
- Uses offline LLM ranking scores to construct pairwise constraints, avoiding inference-time latency while injecting semantic priors
- Targeted augmentation for sparse regions: explicitly generates synthetic LLM supervision for cold-start users and long-tail items to fill gaps in training data
Architecture
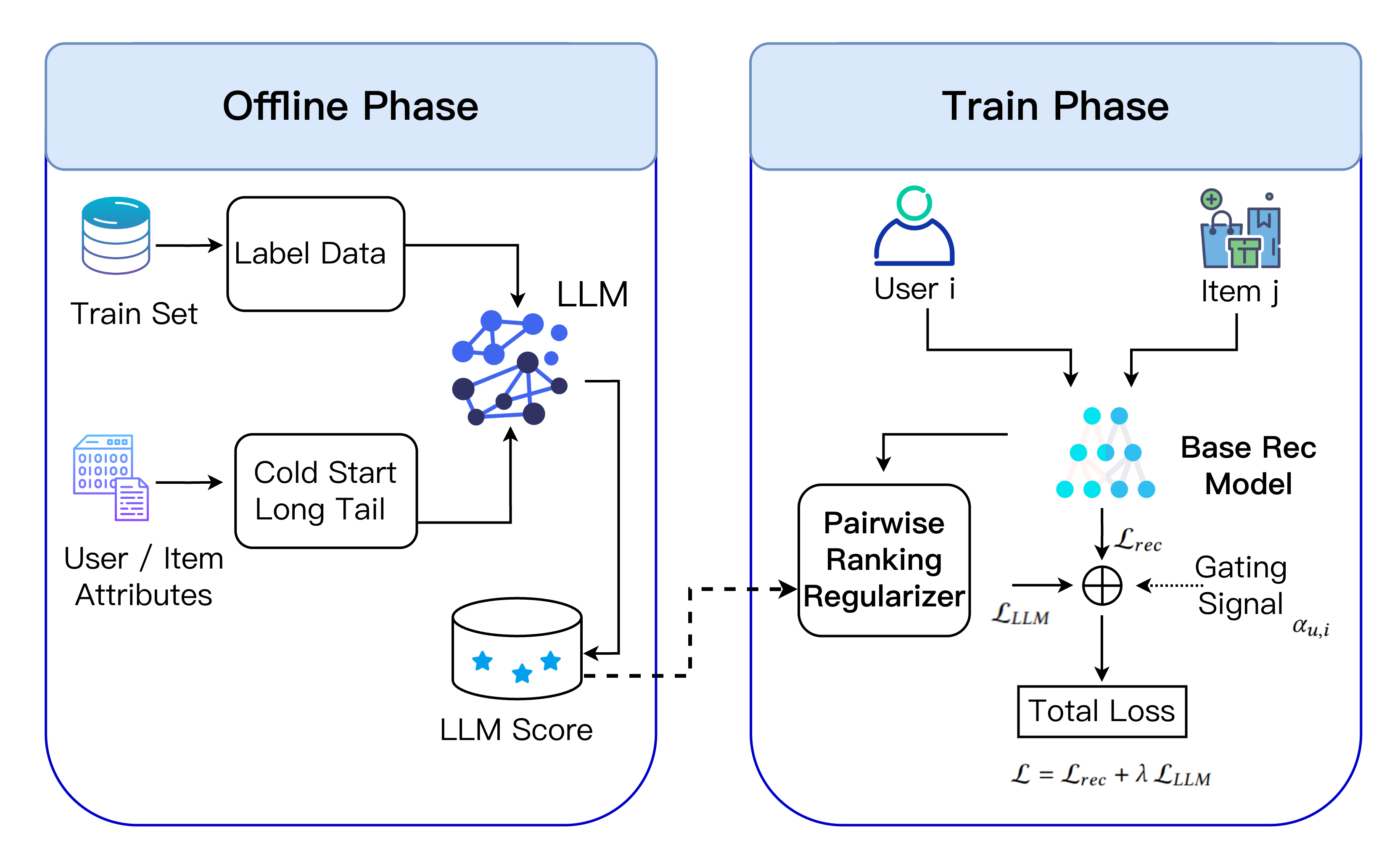
The S-LLMR training framework. It shows the Base Recommender and the Gating Mechanism operating in parallel. The Gating Mechanism takes uncertainty and sparsity signals to output a weight 'alpha'. This weight scales the Pairwise Ranking Loss derived from Offline LLM Scores.
Evaluation Highlights
- Outperforms global distillation (KD) and LLM-CF baselines across 6 different backbones (e.g., DeepFM, DIN) on 3 Amazon datasets
- Achieves substantial gains in sparse regimes: AUC improvements of 0.007–0.01 on Sports & Outdoors for semantically dependent models like AutoInt
- Consistent improvements in cold-start (users < 3 items) and long-tail (bottom 20% items) scenarios where standard models fail
Breakthrough Assessment
7/10
Offers a pragmatic solution to the 'LLM reliability' problem in recommendation. While methodologically simple (gating + regularization), it effectively addresses the downsides of global distillation and shows consistent gains.