📝 Paper Summary
Sequential Recommendation
Generative Recommendation
CALRec adapts generative LLMs for sequential recommendation using a two-tower contrastive alignment objective alongside next-item generation, refined through a two-stage fine-tuning process.
Core Problem
Pretrained LLMs lack specific understanding of user sequential behavior and domain-specific item attributes, while standard next-token prediction losses fail to capture high-level user-item alignment.
Why it matters:
- Traditional ID-based recommenders struggle with dynamic user interests and lack semantic understanding of item content
- Directly applying LLMs to recommendation often yields suboptimal results without domain adaptation or structural alignment
- Pure text-based recommendation avoids the cold-start issues associated with fixed ID embeddings
Concrete Example:
A user buys a hammer, then nails. A standard LLM might predict generic text continuation. CALRec aligns the user's history embedding (hammer, nails) directly with the target item embedding (wood glue) via contrastive loss to ensure the generated text actually describes the relevant next item.
Key Novelty
Contrastive Aligned Generative LLM Recommendation (CALRec)
- Combines standard next-token generation loss with auxiliary contrastive losses (InfoNCE) that align user history representations with target item representations in a shared latent space
- Implements a two-stage fine-tuning strategy: first joint training across multiple categories for general patterns, then category-specific refinement
- Uses a 'quasi-round-robin' BM25 retrieval mechanism to map generated text descriptions back to specific items in the corpus
Architecture
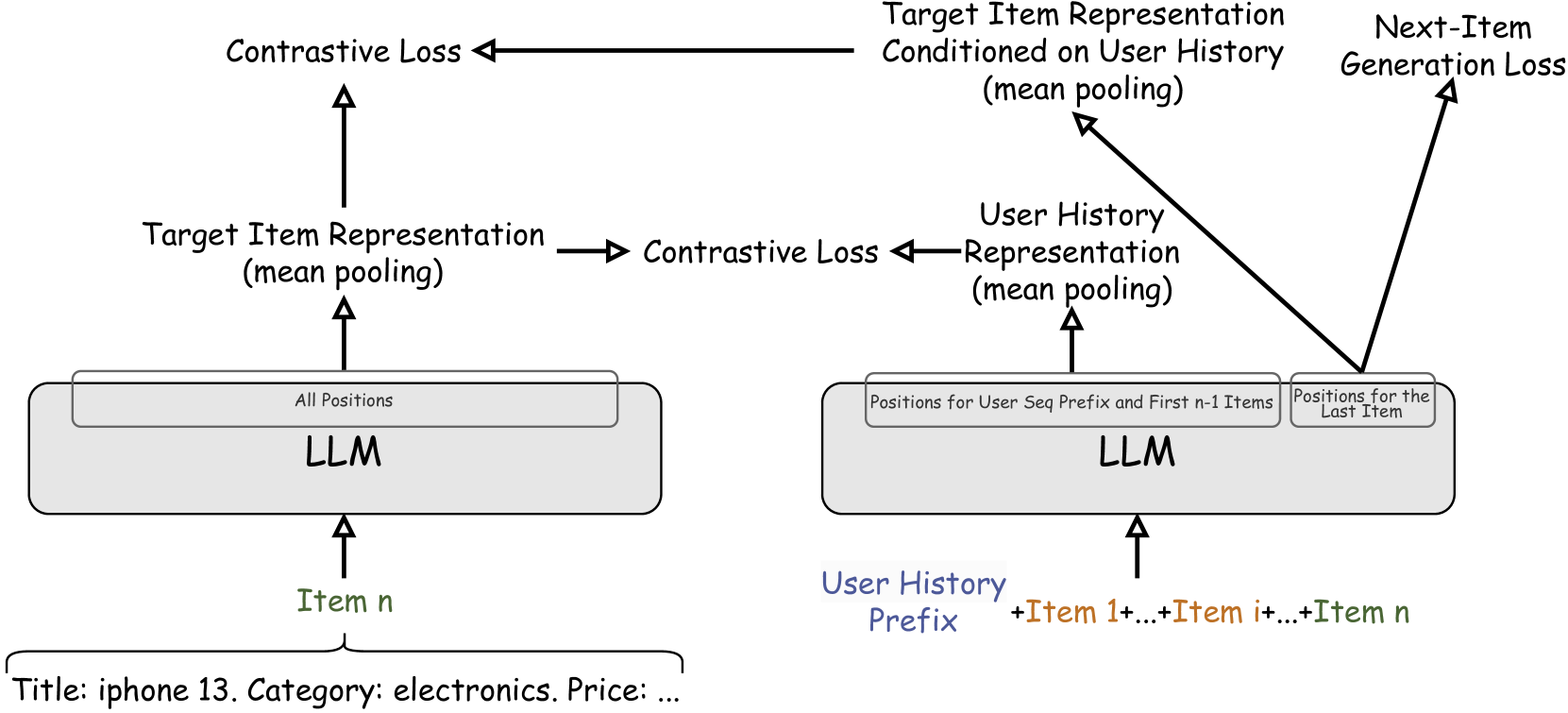
The overall framework of CALRec, illustrating the prompt structure, the two-tower contrastive alignment, and the training objectives.
Evaluation Highlights
- +37% improvement in Recall@1 compared to state-of-the-art baselines on Amazon Review datasets
- +24% improvement in NDCG@10 compared to state-of-the-art baselines on Amazon Review datasets
- Outperforms both traditional sequential models (SASRec) and LLM-based approaches (GPT4Rec) across five domain categories
Breakthrough Assessment
7/10
Strong empirical gains and a sensible integration of contrastive learning with generative LLMs. While the components (contrastive loss, two-stage tuning) are known, their specific application to text-based sequential RecSys is effective.