📝 Paper Summary
Sequential Recommendation
LLM Adaptation
Parameter-Efficient Fine-Tuning
Laser adapts frozen LLMs for sequential recommendation by adding trainable prefix/suffix tokens and using a Mixture-of-Experts transformer to integrate user-specific collaborative signals.
Core Problem
Existing LLM-based recommenders are resource-heavy and integrate collaborative signals via simple linear projections, failing to capture diverse user characteristics.
Why it matters:
- Traditional ID-based methods miss rich semantic information in item descriptions
- Standard LLM fine-tuning is computationally expensive and struggles to align language space with recommendation space
- Simple projections of collaborative signals ignore the complexity of different user types, leading to suboptimal personalization
Concrete Example:
A user who buys 'Kaytee Aspen Bedding' and 'KONG Dog Toy' has specific pet-owner traits. A standard LLM might just see text, while a simple projection mixes all user signals uniformly. Laser uses specific 'experts' to process this pet-owner signal differently from a tech-buyer signal.
Key Novelty
Bi-Tuning with MoE-based Collaborative Integration (Laser)
- Bi-Tuning: Freezes the LLM and tunes only added 'virtual tokens' at the start (prefix) and end (suffix) of the input to adapt the model to recommendation tasks efficiently
- M-Former: An MoE-based module that selects specific 'query experts' to process ID-based collaborative signals, ensuring different user types are handled by specialized parameters before integration into the LLM
Architecture
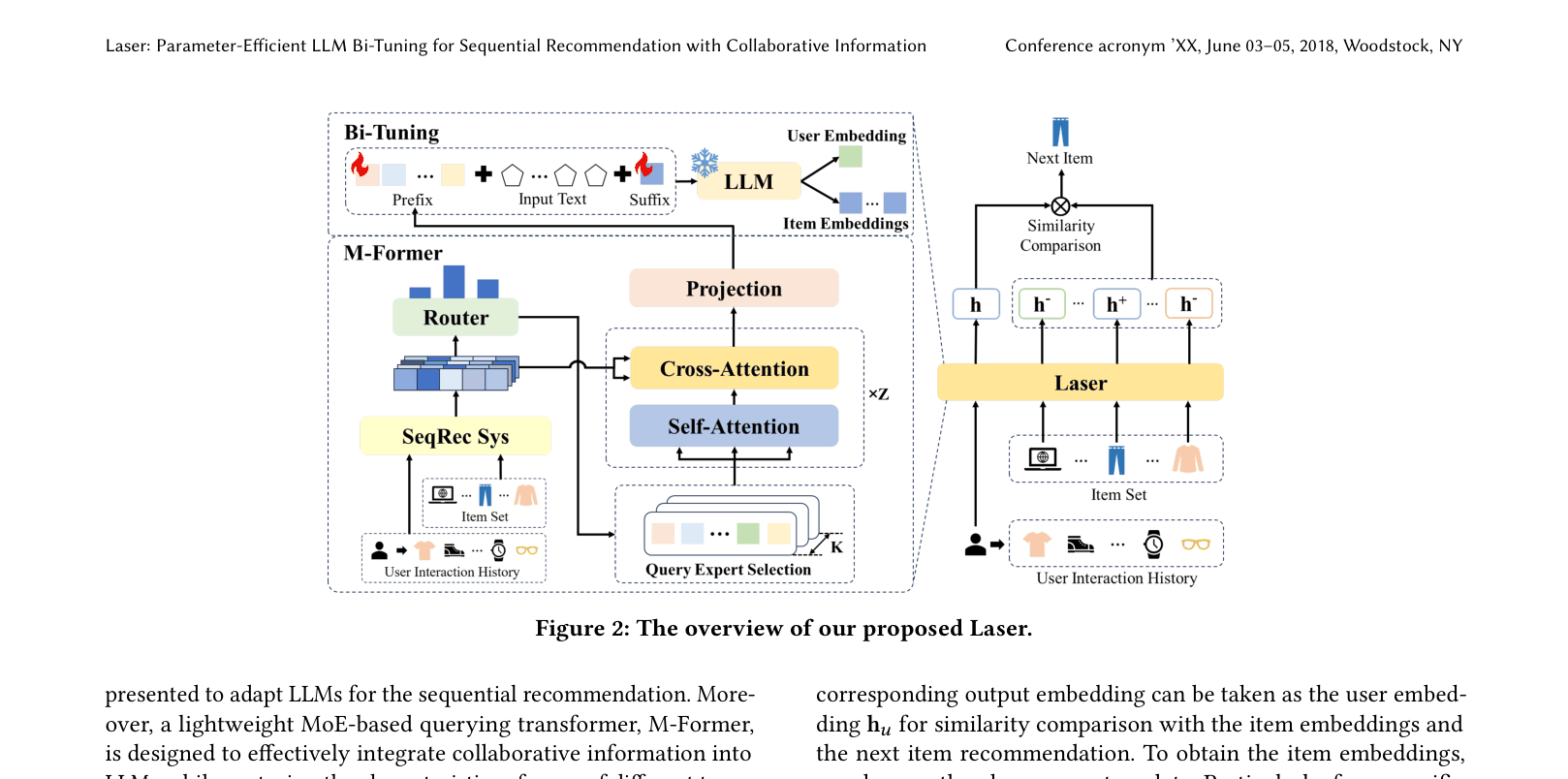
The Laser framework overview, detailing the input processing, M-Former module, and Bi-Tuning mechanism.
Evaluation Highlights
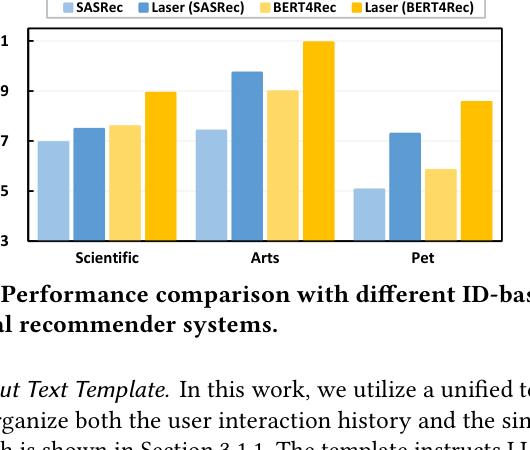
- +13.27% NDCG@10 improvement on Pet Supplies dataset compared to the second-best baseline (LlamaRec)
- +17.65% MRR improvement on Scientific dataset compared to the best traditional method (SASRec)
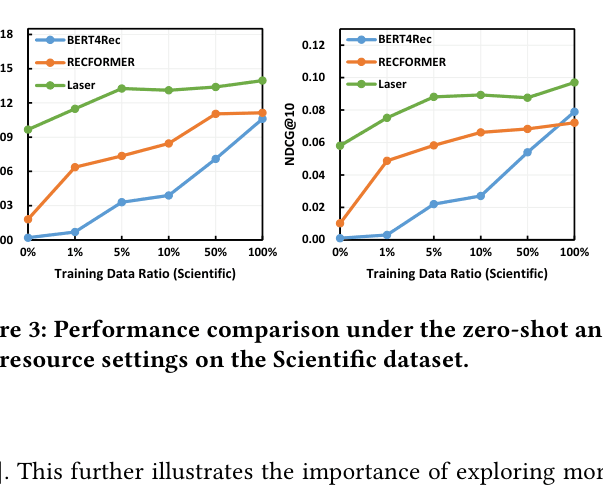
- Zero-shot performance on Scientific dataset (Recall@10 ~0.97) surpasses baselines trained on 100% of data using only 5% of training data
Breakthrough Assessment
7/10
Strong empirical gains and a sensible architecture for combining ID-based signals with LLMs. The Bi-Tuning and MoE integration are effective, though the core concept of soft prompting is established.