📝 Paper Summary
LLM-based Recommendation (LLMRec)
Collaborative Filtering
Multimodal Recommendation
CoLLM integrates collaborative information into LLMs by mapping user/item embeddings from a conventional collaborative filtering model into the LLM's token space via an MLP.
Core Problem
Existing LLM-based recommenders rely heavily on text semantics and struggle to capture collaborative information (user-item interaction patterns), leading to suboptimal performance for warm-start users/items.
Why it matters:
- Pure text-based LLMs miss crucial behavioral patterns hidden in interaction history that text descriptions alone cannot capture
- Current methods fail to match traditional collaborative filtering models in warm-start scenarios where interaction data is rich
- Directly learning ID embeddings in LLMs reduces scalability and compression rates due to tokenization redundancy
Concrete Example:
Two items with similar text descriptions (e.g., two sci-fi movies) might appeal to very different user groups based on interaction history. A standard LLM sees them as textually similar and misses the distinction, whereas CoLLM uses collaborative embeddings to differentiate them based on who actually consumed them.
Key Novelty
Collaborative Information as a Distinct Modality
- Treats collaborative embeddings (from models like Matrix Factorization or LightGCN) as a separate modality, similar to how multimodal LLMs handle images
- Maps these external embeddings into the LLM's input space using a lightweight MLP projector, rather than training ID embeddings from scratch within the LLM
- Uses a two-step tuning process: first tuning the LLM with LoRA for general recommendation capabilities, then tuning the mapping module to align collaborative signals
Architecture
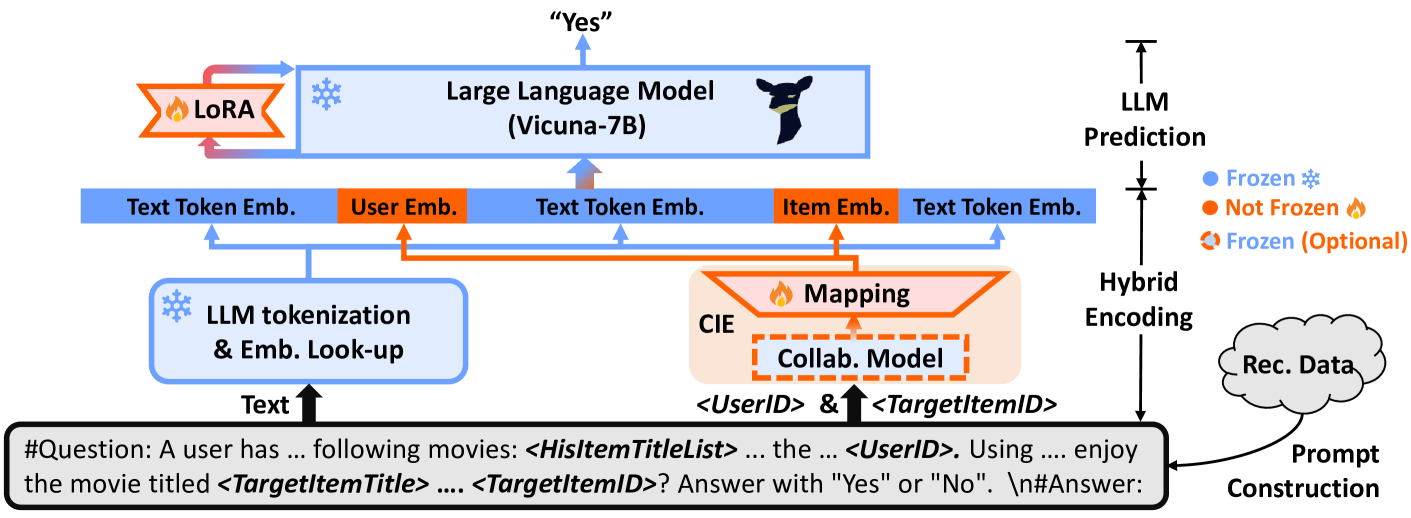
The CoLLM model architecture detailing the flow from prompt construction to prediction.
Evaluation Highlights
- Outperforms TALLRec by substantial margins in warm-start scenarios (e.g., +69.9% improvement on Yelp dataset)
- Surpasses traditional collaborative baselines like LightGCN in cold-start scenarios where interaction data is scarce
- Achieves superior performance with significantly fewer trainable parameters compared to full fine-tuning approaches
Breakthrough Assessment
7/10
Effective bridging of the gap between semantic-rich LLMs and interaction-rich collaborative filtering. The 'collaborative as modality' approach is a smart architectural choice that preserves LLM scalability.