📝 Paper Summary
LLM for Recommendation
Sequential Recommendation
Feature Extraction
RecXplore is a modular framework that systematically disentangles the LLM-based feature extraction pipeline to identify optimal design choices—finding that simple prompt flattening, two-stage fine-tuning, and hybrid PCA-MoE adaptation yield the best performance.
Core Problem
Existing LLM-based recommendation methods tightly couple design decisions (prompts, models, adaptation), making it impossible to isolate which specific components drive performance gains.
Why it matters:
- Current research proposes monolithic architectures without justifying individual design choices, hindering reproducibility and fair comparison
- Practitioners struggle to deploy LLM-enhanced recommenders because it is unclear whether complex prompt engineering or heavy fine-tuning is actually necessary
- The absence of a controlled diagnostic framework prevents understanding the true source of empirical improvements in sequential recommendation
Concrete Example:
A researcher might attribute performance gains to a complex 'knowledge-enhanced' prompt strategy, when in reality, the gain comes solely from the downstream MLP adapter used to process the embedding, but the monolithic design hides this distinction.
Key Novelty
RecXplore: A Modular Diagnostic Framework
- Factorizes the recommendation pipeline into four isolated modules (Data Processing, Feature Extraction, Adaptation, Sequential Modeling) to allow controlled variable experiments
- Systematically evaluates mutually exclusive design choices (e.g., pooling methods, fine-tuning strategies) under a unified protocol to distill 'best practices'
- Demonstrates that assembling simple, optimized components often outperforms complex, over-engineered architectures without requiring new model designs
Architecture
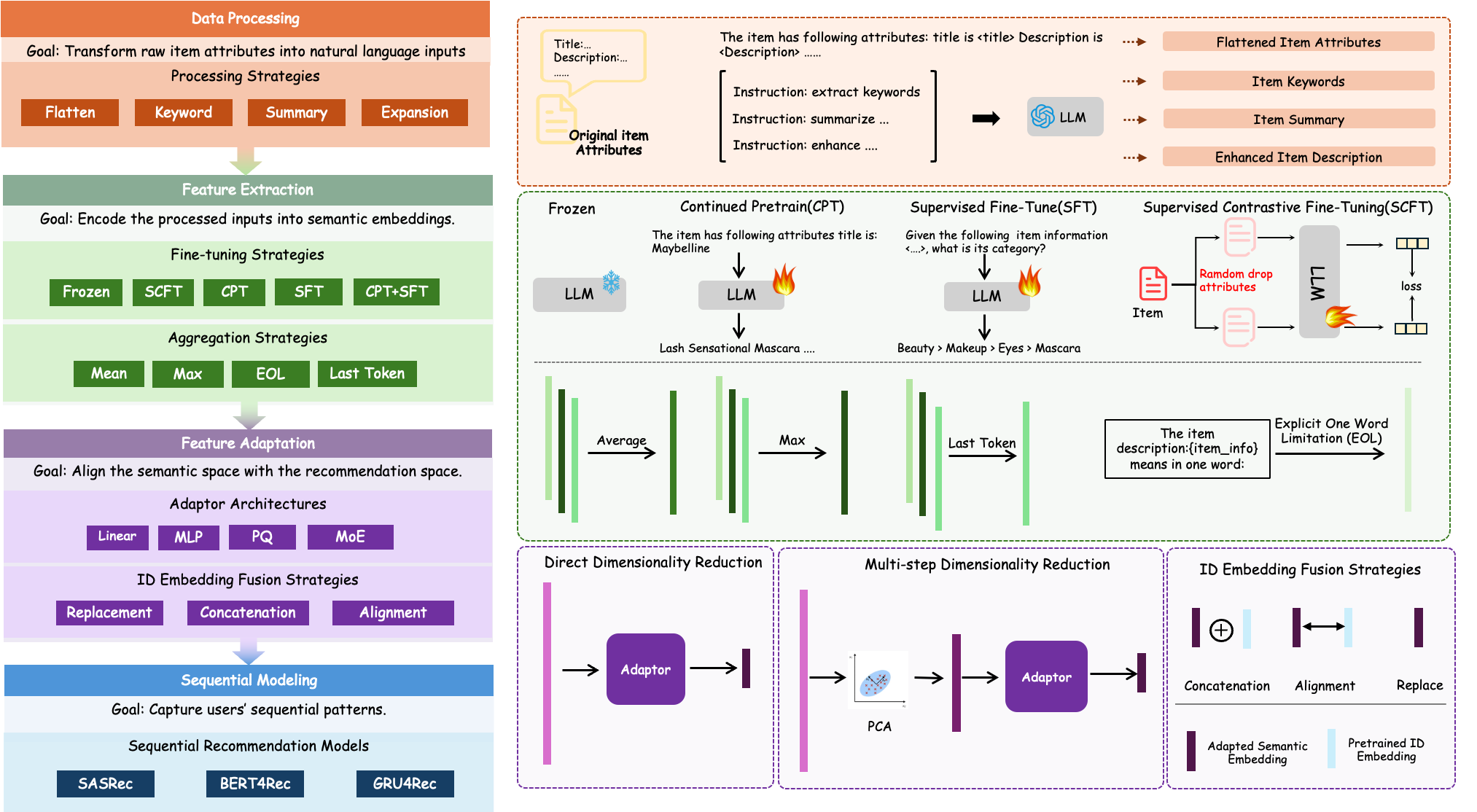
The RecXplore Framework Architecture showing the four decoupled modules.
Evaluation Highlights
- Achieves up to 18.7% relative improvement in NDCG@5 over strong baselines by assembling best practices
- Achieves up to 15.1% relative improvement in HR@5 over strong baselines
- Two-stage adaptation (CPT + SFT) consistently outperforms single-stage methods for generating transferable semantic representations
Breakthrough Assessment
7/10
While not introducing a new architecture, the systematic decomposition and rigorous empirical analysis provide highly valuable, actionable insights that debunk complexity myths in the field (e.g., complex prompts are worse than simple flattening).