📝 Paper Summary
Reinforcement Learning for LLMs
Theoretical Analysis of RL
Process vs. Outcome Rewards
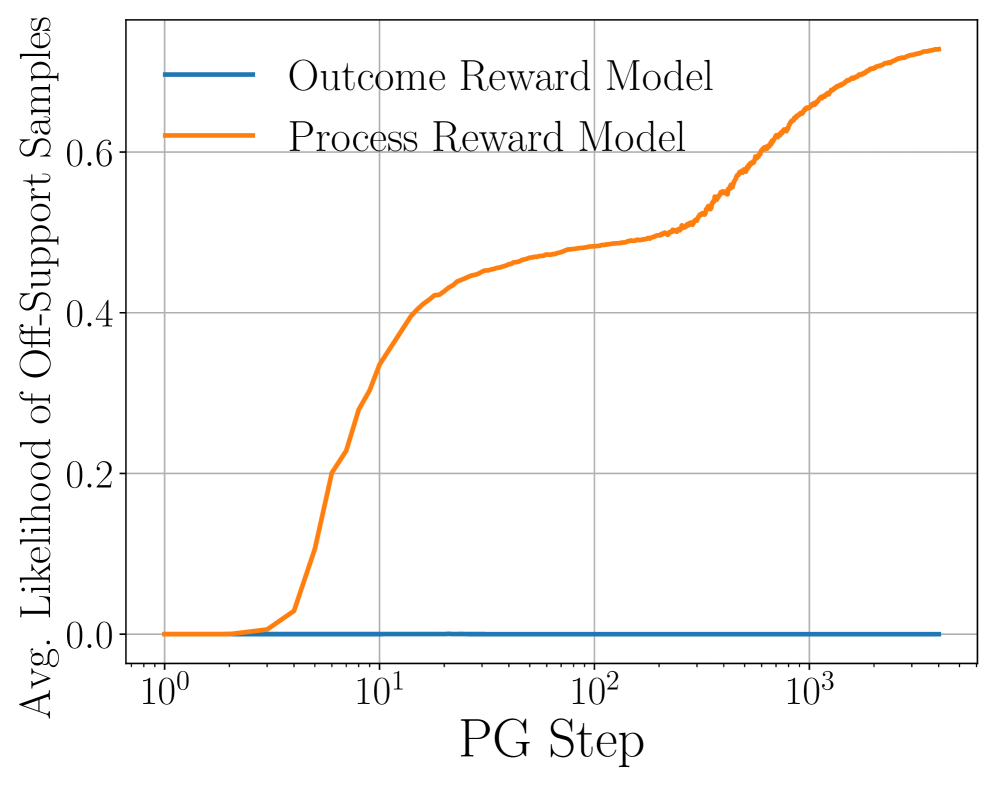
Theoretical analysis proves that outcome-based RL is inefficient for generating responses outside the base model's support, a barrier that process rewards overcome by leveraging token-level feedback.
Core Problem
RL with outcome rewards (RLHF) typically fails to generate correct responses for prompts where the base model has negligible likelihood (off-support), merely sharpening the existing distribution.
Why it matters:
- Current LLM post-training heavily relies on outcome rewards, but it is unclear if this can genuinely create new knowledge or just refine existing capabilities
- Understanding the theoretical limits of RL post-training is crucial for designing algorithms that can generalize beyond pre-training data
- Prior theory works on RL post-training often ignore the specific role of the base model's initial support in determining sample complexity
Concrete Example:
Consider a sequence of length N where the correct response has exponentially small probability under the base model (e.g., a complex reasoning chain). Outcome-based PG requires exponentially many samples to learn this, effectively failing, while process-based PG can learn it with samples linear in N.
Key Novelty
The Base Model Barrier and Likelihood Quantile
- Identifies a 'Likelihood Quantile' (LQ) property of the base model that governs the sample complexity of outcome-based post-training
- Proves that while outcome rewards face an exponential barrier for off-support samples, process rewards (verifying each token) break this curse of dimensionality
Architecture
Conceptual diagram contrasting 'On-Support' vs 'Off-Support' learning dynamics.
Evaluation Highlights
- Outcome-based PG achieves error ε with Õ(1/(αγ²ε)) samples, efficient only if base likelihood α is non-trivial (polynomial in N)
- Online PG with uniform policy achieves minimax optimal mistake bound Õ(k^N/γ²), matching information-theoretic limits
- Process rewards reduce the worst-case sample complexity dependence on sequence length N from exponential to linear
Breakthrough Assessment
9/10
Provides a rigorous theoretical foundation explaining the empirically observed limitations of RLHF (outcome rewards) and formally proving the necessity of process rewards for true generalization.