📝 Paper Summary
Multimodal Reasoning
Chart Understanding
Reinforcement Learning from Verifiable Rewards (RLVR)
Chart-RL enhances vision-language models' chart comprehension by using reinforcement learning with mathematically verifiable rewards on complex reasoning tasks, achieving robust generalization without large-scale supervision.
Core Problem
Existing Vision-Language Models (VLMs) struggle with multi-step reasoning on charts because Supervised Fine-Tuning (SFT) often leads to overfitting on specific templates and fails to generalize to unseen chart types or complex queries.
Why it matters:
- Charts compress dense information into diverse visual structures (bars, pies, plots), making them fundamentally harder than natural images for standard VLMs to interpret reliably.
- SFT methods frequently suffer from catastrophic forgetting and poor transferability, meaning a model trained on bar charts might fail on scatter plots or complex math questions.
- Current approaches rely on massive curated datasets which are costly to produce and may still miss real-world complexity.
Concrete Example:
When asked a multi-step question like 'What is the ratio of the highest value in 2020 to the lowest in 2021?', an SFT-trained model might extract one number correctly but fail the arithmetic or the comparison, whereas Chart-RL learns the full reasoning path via reward feedback.
Key Novelty
Reinforcement Learning with Verifiable Rewards (RLVR) for Charts
- Treats chart QA as a reasoning task with deterministic answers (e.g., numerical values), allowing the use of rule-based accuracy rewards instead of human preference labels.
- Uses Group Relative Policy Optimization (GRPO) to encourage the model to explore reasoning paths that lead to the correct mathematical answer, rather than just imitating training text.
- Demonstrates that training on a small set of complex, multi-step reasoning tasks (Hard Task) transfers better to general chart understanding than training on thousands of simple extraction tasks.
Architecture
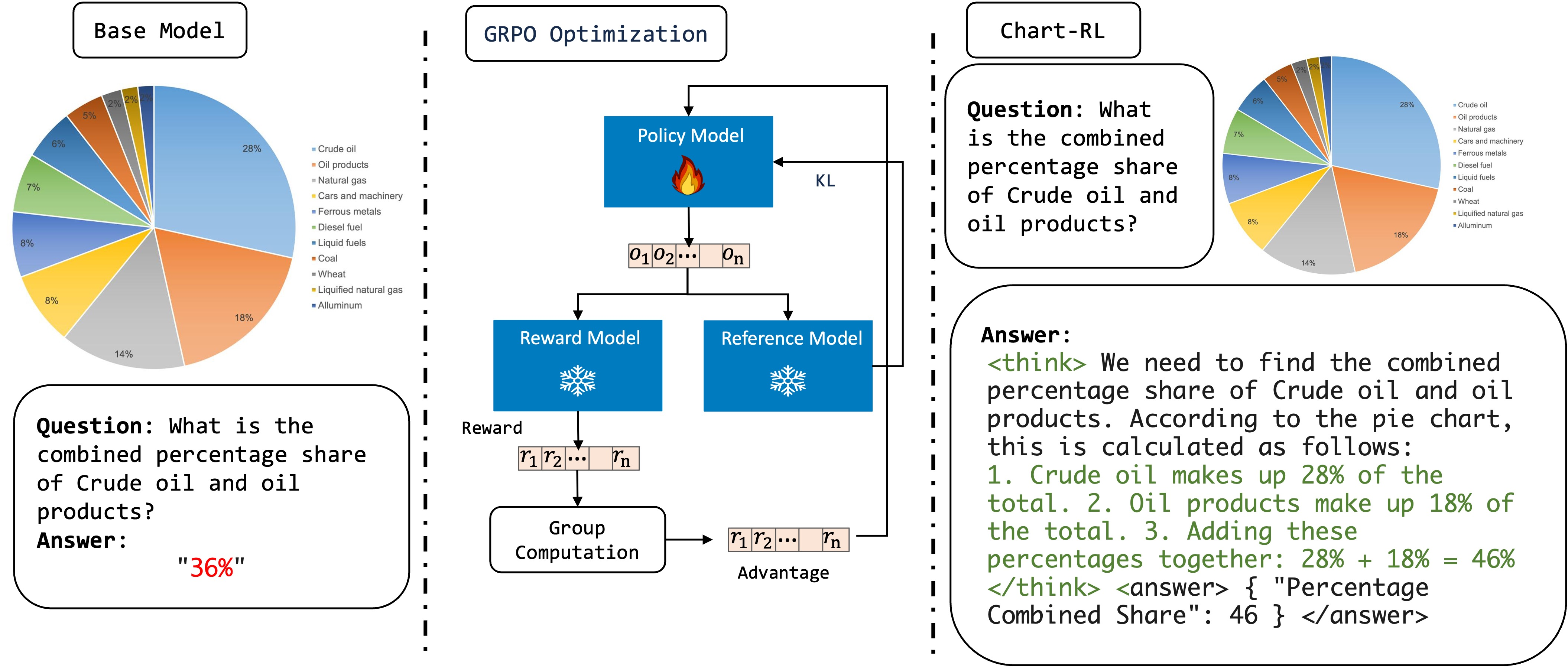
The Chart-RL training framework using GRPO with verifiable rewards.
Evaluation Highlights
- +16.7% relative improvement on MultiChartQA compared to Supervised Fine-Tuning (SFT) using the Qwen2.5-VL-3B-Instruct baseline.
- +11.5% relative improvement on ChartInsights compared to SFT.
- Achieves strong performance with only 10 complex training examples, significantly outperforming models trained on 6,000+ simple examples.
Breakthrough Assessment
8/10
Significant for demonstrating that RLVR (popular in LLM math) works effectively for VLM chart reasoning. The finding that task complexity outweighs data quantity (10 hard vs 6000 easy samples) is a strong efficiency result.