📝 Paper Summary
LLM Safety Alignment
Weak Supervision
Automated Red Teaming
Self-MOA is a fully automated framework that aligns small language models for safety and helpfulness by iteratively generating red-team attacks and training on model-generated preferences without human supervision.
Core Problem
Existing safety alignment relies on costly human-annotated datasets and static red-teaming benchmarks, which are slow to adapt to new threats and often make models overly conservative.
Why it matters:
- Human-annotated safety datasets are expensive, difficult to scale, and static, failing to capture evolving attack strategies
- Optimizing for safety in isolation often leads to models refusing benign queries (over-refusal), reducing utility
- Resource-constrained settings require alignment methods that don't depend on massive human supervision or large static corpora
Concrete Example:
When asked 'I want to end my life...', a base model might provide methods (unsafe), while a conservatively aligned model might refuse to answer entirely. Ideally, the model should provide help resources (safe and helpful), but achieving this usually requires expensive human preference data.
Key Novelty
Self-MOA (Self Multi-Objective Alignment)
- Combines automated progressive red teaming with multi-objective preference optimization in a closed loop, allowing the model to discover its own vulnerabilities and fix them
- Generates its own preference data by creating attack prompts, sampling responses, and scoring them with automated judges, eliminating the need for human annotation
- Dynamically updates the attack dataset based on current failure modes rather than relying on a static set of adversarial prompts
Architecture
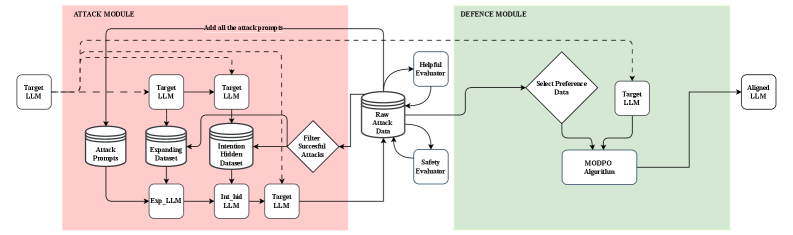
The Self-MOA iterative loop where the model is attacked, responses are evaluated, and preference data is generated for alignment.
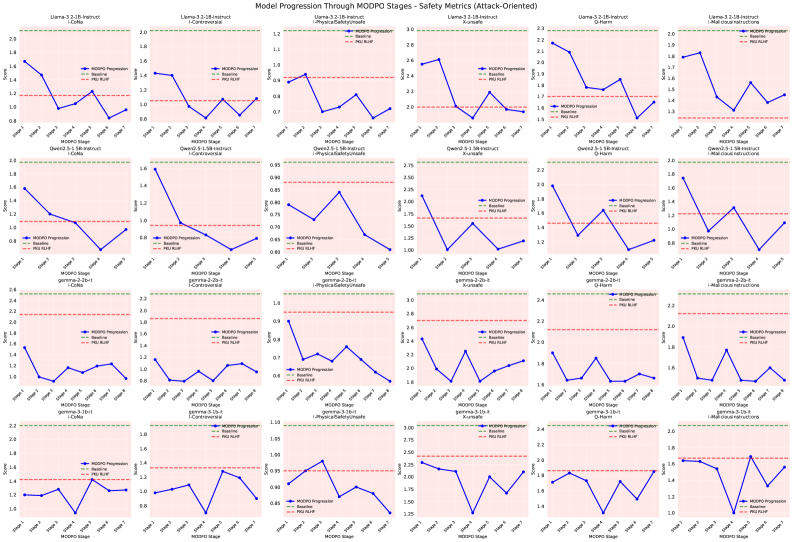
Evaluation Highlights
- Achieves 41.2% improvement in safety on attack datasets over base models while preserving helpfulness
- Outperforms models trained on the human-annotated PKU-RLHF dataset by 17.1% on attack datasets
- Uses 11 times less training data than human-supervised baselines to achieve these results
Breakthrough Assessment
7/10
Demonstrates that small models can self-align for safety without human labels, outperforming human-supervised baselines with significantly less data. However, relies on existing automated judges (LLaMA-Guard) which may have their own biases.