📝 Paper Summary
Machine Unlearning
Privacy in LLMs
DeepCUT removes specific data from a language model by optimizing its latent space, pushing 'forgotten' samples away from their class cluster while maintaining performance on remaining data.
Core Problem
Existing unlearning methods for LLMs focus on output probability distributions (like KL-divergence) without explicitly optimizing the geometric distribution of samples in the model's latent space.
Why it matters:
- LLMs memorize sensitive user data (names, medical records), violating privacy laws like GDPR's 'right to be forgotten'
- Retraining massive models from scratch to remove single data points is computationally infeasible
- Current output-based unlearning fails to remove the deep semantic traces of sensitive data that reside in the embedding space
Concrete Example:
If a user revokes consent for their medical records used to train an NER model, standard unlearning might adjust the final classification probabilities but leave the distinct embedding of their specific disease history intact in the latent space.
Key Novelty
Latent Space Contrastive Unlearning
- Treats the sample to be forgotten (anchor) as a negative example for its own original class in the embedding space
- Pushes the anchor away from other samples of the same class (unlearning) while pulling it closer to samples of different classes
- Simultaneously maintains the clustering of remaining data to preserve model utility
Architecture
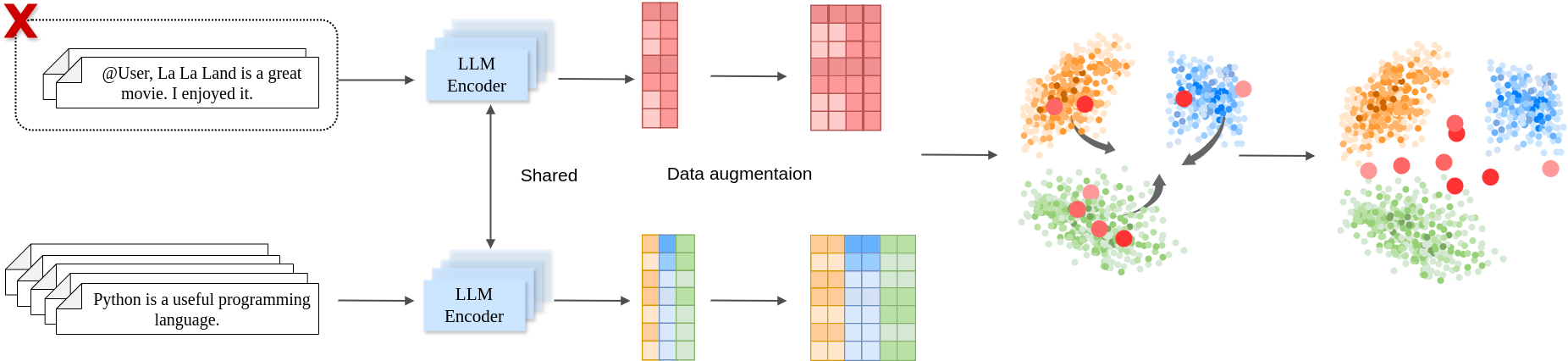
Overview of the DeepCUT framework operating within the embedding space of an LLM Encoder.
Evaluation Highlights
- Consistent improvement over baseline methods (Naive Unlearning, SISA, etc.) on real-world datasets
- Effectively removes discriminative features of specific samples without degrading performance on remaining data
- Demonstrated specifically on the Named Entity Recognition (NER) task
Breakthrough Assessment
6/10
Applies established contrastive learning principles to the unlearning problem in a logical way. While the conceptual framework is sound, the paper lacks reported author details and specific quantitative results in the provided text.