📝 Paper Summary
Spatio-temporal representation learning
Earth observation
Ecological forecasting
DeepEarth introduces Earth4D, a planetary-scale 4D hash encoding that efficiently maps space-time coordinates to embeddings, enabling a multi-modal world model to forecast ecological states with high precision.
Core Problem
Existing Earth observation models struggle to efficiently scale high-resolution representations across both vast planetary spaces and long temporal periods while handling multi-modal data.
Why it matters:
- Accurate ecological forecasting (e.g., wildfire risk) requires precise modeling of conditions that vary rapidly in both space and time.
- Traditional positional encoders fail to handle the collision trade-offs inherent in mapping the entire Earth's surface over centuries at sub-meter resolution.
- Current foundation models often require massive pre-training data yet still lack the specialized spatio-temporal resolution needed for localized predictions.
Concrete Example:
When predicting Live Fuel Moisture Content (LFMC) for wildfire risk, a standard model might conflate measurements from the same location at different times. DeepEarth uses 4D hashing to distinctively encode (lat, lon, elev, time), correctly separating a wet winter measurement from a dry summer one at the exact same GPS coordinate.
Key Novelty
Earth4D: Learnable 4D Multi-Resolution Hash Encoding
- Extends 3D hash encoding to 4D by concatenating features from one spatial grid (xyz) and three spatio-temporal grids (xyt, yzt, xzt), enabling efficient space-time indexing.
- Integrates learned hash probing to dynamically resolve hash collisions, allowing the model to learn optimal memory allocation patterns rather than relying on static hashing.
- Fuses these 4D embeddings with multi-modal data (vision, language) in a self-supervised autoencoder framework to learn unified Earth representations.
Architecture
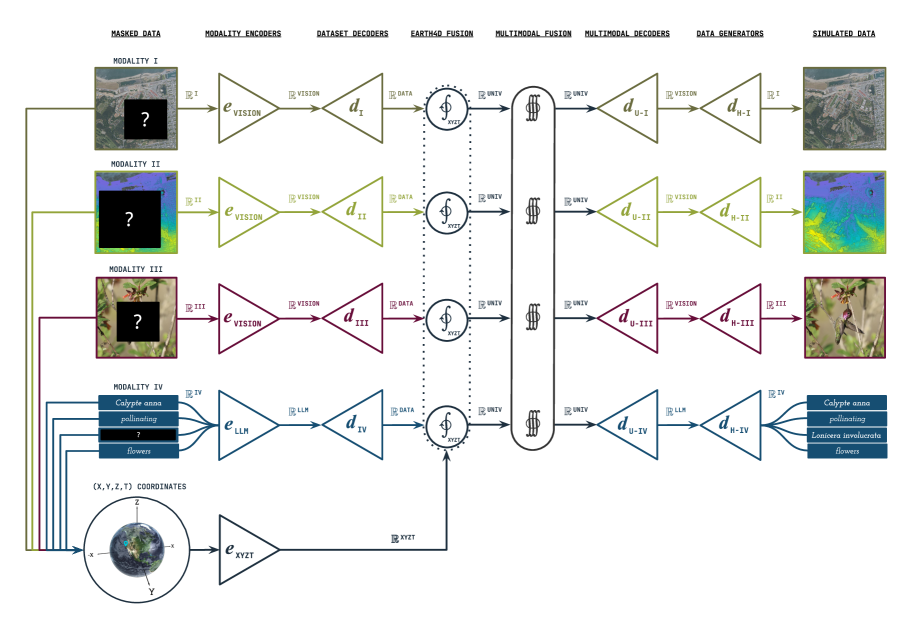
System architecture of DeepEarth and the internal structure of the Earth4D encoder.
Evaluation Highlights
- +35.0% improvement in R² (0.783 vs 0.58) on Live Fuel Moisture Content prediction by adding learned hash probing to standard hash encoding.
- Surpasses the Galileo foundation model (MAE 11.7pp vs 12.6pp) using only coordinates and species embeddings, despite Galileo using massive multi-modal remote sensing data.
- Achieves 99.3% parameter reduction (5M vs 800M) while maintaining high accuracy (R² 0.668), enabling efficient planetary-scale modeling.
Breakthrough Assessment
8/10
Significant architectural innovation in 4D encoding that outperforms larger foundation models on key ecological tasks with far less data/compute. The learned hashing for space-time collisions is a strong technical contribution.