📊 Experiments & Results
Evaluation Setup
Pre-training 8B models from scratch with fixed compute/FLOPs and evaluating on downstream benchmarks
Benchmarks:
- MMLU (Knowledge and reasoning (5-shot))
- GSM8k (Math word problems (8-shot))
- HumanEval (Code generation (0-shot))
- LAMBADA (Language modeling / next word prediction)
- HellaSwag (Common sense reasoning)
Metrics:
- Accuracy (aggregated across 30 tasks)
- Bits-Per-Byte (BPB) for language modeling loss
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison of 8B models trained with SuperBPE (t=180k) vs. Standard BPE baseline across varying task categories. | ||||
| Average (30 tasks) | Accuracy | 55.5 | 59.5 | +4.0 |
| MMLU | Accuracy (5-shot) | 44.9 | 53.1 | +8.2 |
| GSM8k | Accuracy (8-shot) | 39.6 | 43.7 | +4.1 |
| HumanEval | Pass@1 (0-shot) | 24.6 | 25.2 | +0.6 |
| LAMBADA | Accuracy (0-shot) | 75.8 | 70.6 | -5.2 |
| Encoding efficiency and inference compute improvements. | ||||
| Held-out Corpus | Inference FLOPs reduction | 0 | 27 | 27 |
Experiment Figures

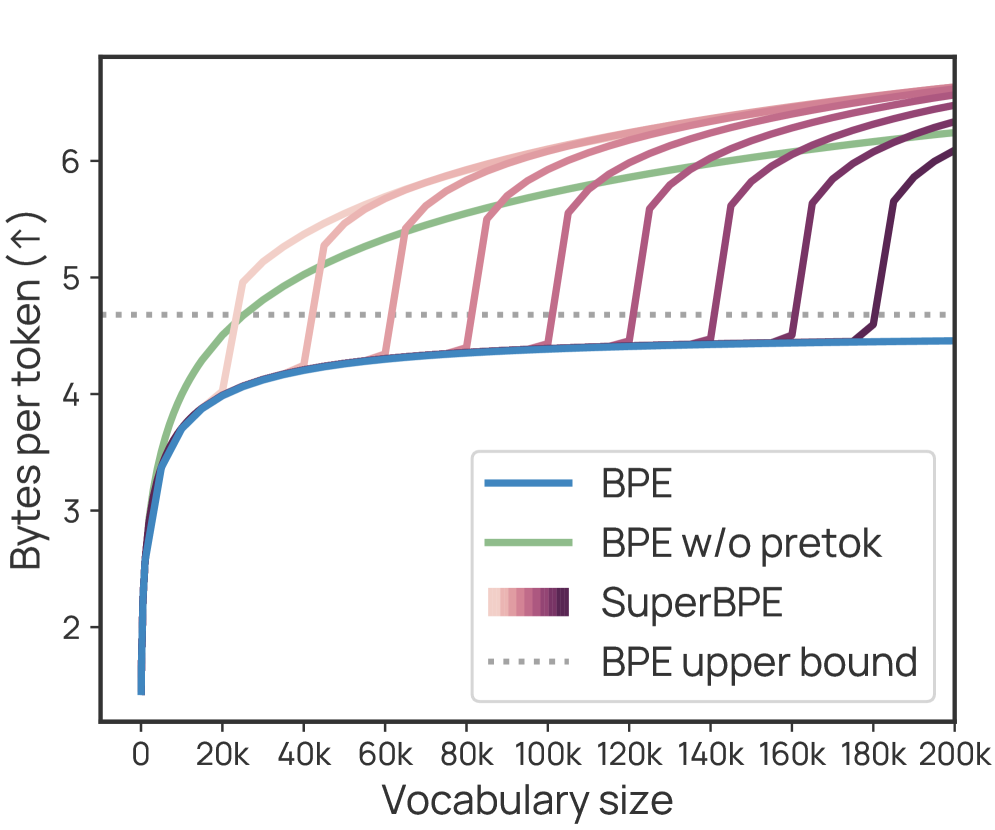
Bytes-per-token (encoding efficiency) vs. Vocabulary Size for BPE vs. SuperBPE
Average Downstream Task Accuracy over Pre-training Tokens
Distribution of Per-Token Bits-Per-Byte (BPB) Loss
Main Takeaways
- SuperBPE significantly outperforms BPE on downstream tasks while reducing inference costs, challenging the subword tokenization status quo.
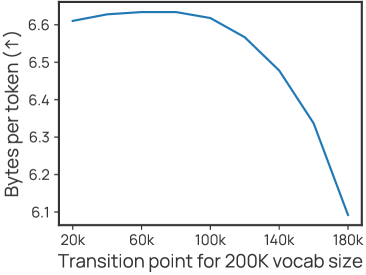
- The 'transition point' (t) allows a trade-off: earlier transitions (e.g., t=80k) yield maximum compression, while later transitions (e.g., t=180k) yield maximum downstream performance gains.
- Qualitative analysis shows SuperBPE tokens capture semantic units like prepositional phrases ('by accident') and multi-word expressions ('search engine'), which BPE splits.
- Despite better task performance, SuperBPE has slightly worse BPB (language modeling loss) because it trivializes the prediction of very common words (e.g., ' of the') by merging them, removing 'easy' wins from the loss calculation.